

< Introduction to Deep Learning >
전반적인 내용정리, 기초.


데이터가 주어졌을때, 컴퓨터가 모델을 만들어 prediction을 할 수 있도록 하는것을 machine-learning이라고 한다.


사실 저런식으로 문제를 풀어내기 위해서는 박사 5년차 정도는 되어야 문제 하나를 잘 풀어낼수 있게 된다고 한다;;

도메인 전문가가 feature-extraction을 해주지 않는 이상 machine-learning작업을 하는 것이 쉽지 않았다. 하지만 이런 부분들을 어떤 frame-work이 대신할수는 없을까 하는 생각에서 나온 것이 deep-learning이다.



인풋의 뉴런은 count하지 않으므로, 6개의 뉴런과, 12+8인 20개의 weight, 그리고 biases는 input->hidden으로 갈때 노드 개수(4) 만큼 필요하고, hidden->output으로 갈 때 역시 마찬가지로 필요하므로(2) 총 6개의 biases가 필요하다.
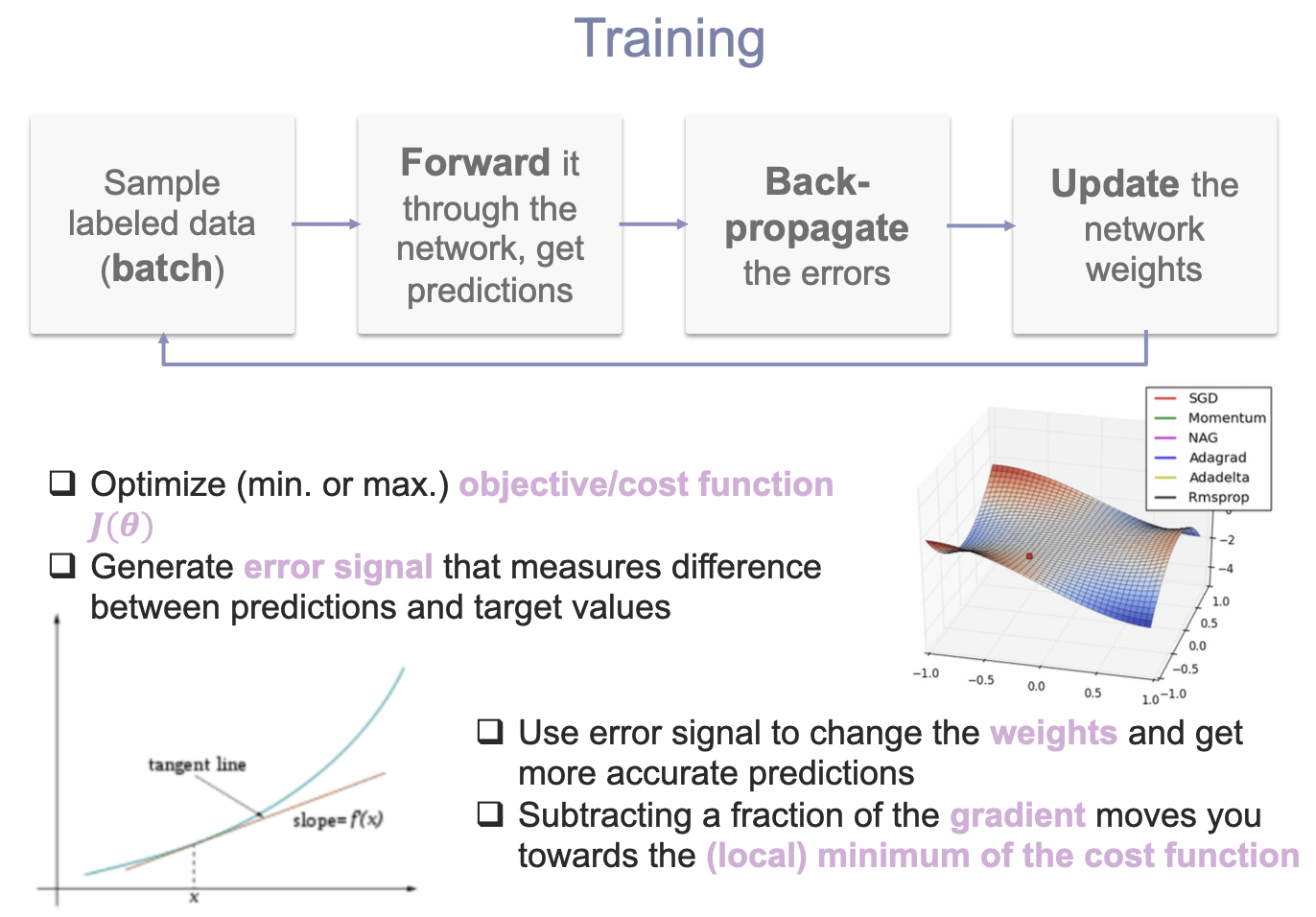
training하는 방법이다. batch, forward,back-propagate,update-weight의 과정을 반복하게 된다. 미분을 했을때, gradient가 0으로 가는 방향으로 weight을 옮겨가는 것이 핵심이다.

전체 뉴럴넷을 L이라고 했을 때, 이 L,즉 cost-function을 최소로 만드는 값을 찾고 싶은 것이다. forward방법이라고 생각해보면, 최종적으로 L의 변화량을 알 수 있다. 거꾸로 이 값을 알고 있다면 노드로 오는 weight의 변화량을 구할 수 있다. 따라서 chain-rule에 따라 역으로 gradient를 계산할 수 있는 것이다.





Activation function 중 ReLU는 gradient vanishing problem을 막아주는 역할을 하기도 한다.


너무 과하게 큰 weight이 있어 비 현실적인 값이 있다면 이를 막는다. training set은 잘 맞는다 하더라도, test set에서 결과값이 안좋게 나오기 때문이다.

이런식으로 value를 잘 분포시키게 되면 important parameter를 들고갈 확률이 높아지기 때문에 더 유리하다.



stride는 filter가 움직이는 단위를 말한다. 2x2,max-pooling, stride 2이므로 두칸씩 옮겨가면서 최대값이 대입될 것이다.



항상 같은 weight을 사용한다는 공통점이 있다.



RNN에서의 약점은 long-dependencies라는 것이 있다. 오래전의 내용에 계속 가중치가 있다는 것이다. 이를 좀더 control할 수 있도록 만든것이 GRU이다.


LSTM도 동일하다. BERT파다가 고생했던게 생각난다...
'[ML] > [Lecture]' 카테고리의 다른 글
| [ML/Lecture] 7. Learning from Examples (Part B) (0) | 2020.06.29 |
|---|---|
| [ML/Lecture] 6. Learning from Examples (Part A) (0) | 2020.06.25 |
| [ML/Lecture] 5. Inference in BN (0) | 2020.06.20 |
| [ML/Lecture] 4. Bayesian Networks (0) | 2020.06.20 |
| [ML/Lecture] 3. Uncertainty (0) | 2020.05.04 |



