
< 실습 - Data LAB 준비하기 >
Cloud Data LAB은 Google Cloud Platform에서 Jupyter notebook을 호스팅된 버전으로 제공한다. 이미 플랫폼에 인증이 되어 있으므로, 클라우드 스토리지, 빅쿼리, 데이터 플로우, 클라우드 ML 엔진 등에 쉽게 접근할 수 있다.
다음 내용은 구글 컴퓨트 엔진 인스턴스에서 클라우드 데이터 랩을 실행하고, 로컬 머신에서 접속하는 방법을 설명한다.
0. 제일 먼저 관련 api 설정을 해 주어야 만사가 평안하다... 아래의 사진에 보이는 Cloud Source Repositories API를 사용설정을 통해 인증해 주고 시작한다.


1. Cloud Shell에 영역 지정, 인스턴스명 지정, 인스턴스 생성
datalab create --zone us-central1-a gcptest1-datalab
2. 클라우드 데이터랩 인스턴스가 접속가능하다는 메세지를 보내면 Cloud Shell의 웹 미리보기를 통해 Cloud Data LAB을 띄운다.


3. 필요한 패키지들을 수동으로 설치하고 코드를 따라가도 되고, 나는 귀찮으니 저자의 repository에 있는 exploration.ipynb 파일을 데이터랩에 로드해서 사용하기로 했다. 먼저 github의 저자의 레퍼지토리에서 raw file을 다운로드해준다.
※ 포맷은 페이지 소스로, 내보내는 이름도 .ipynb로 내보내기 바란다.
이후에 데이터랩에 들어가서 upload로 다운받은 파일들을 업로드 해 준다.

그러면 아래와 같이 정상적으로 저자의 exploration.ipynb file이 올라간 것을 볼 수 있다. 이후에는 천천히 notebook을 읽어보면서 관련 데이터들을 분석해 보도록 하자

< 실습 - exploartion.ipynb 뜯어보기 >
클라우드 쉘에 접속해서 다음과 같은 명령어로 생성해 놓았었던 VM인스턴스에 접속한다.
datalab connect --zone $ZONE $INSTANCE_NAME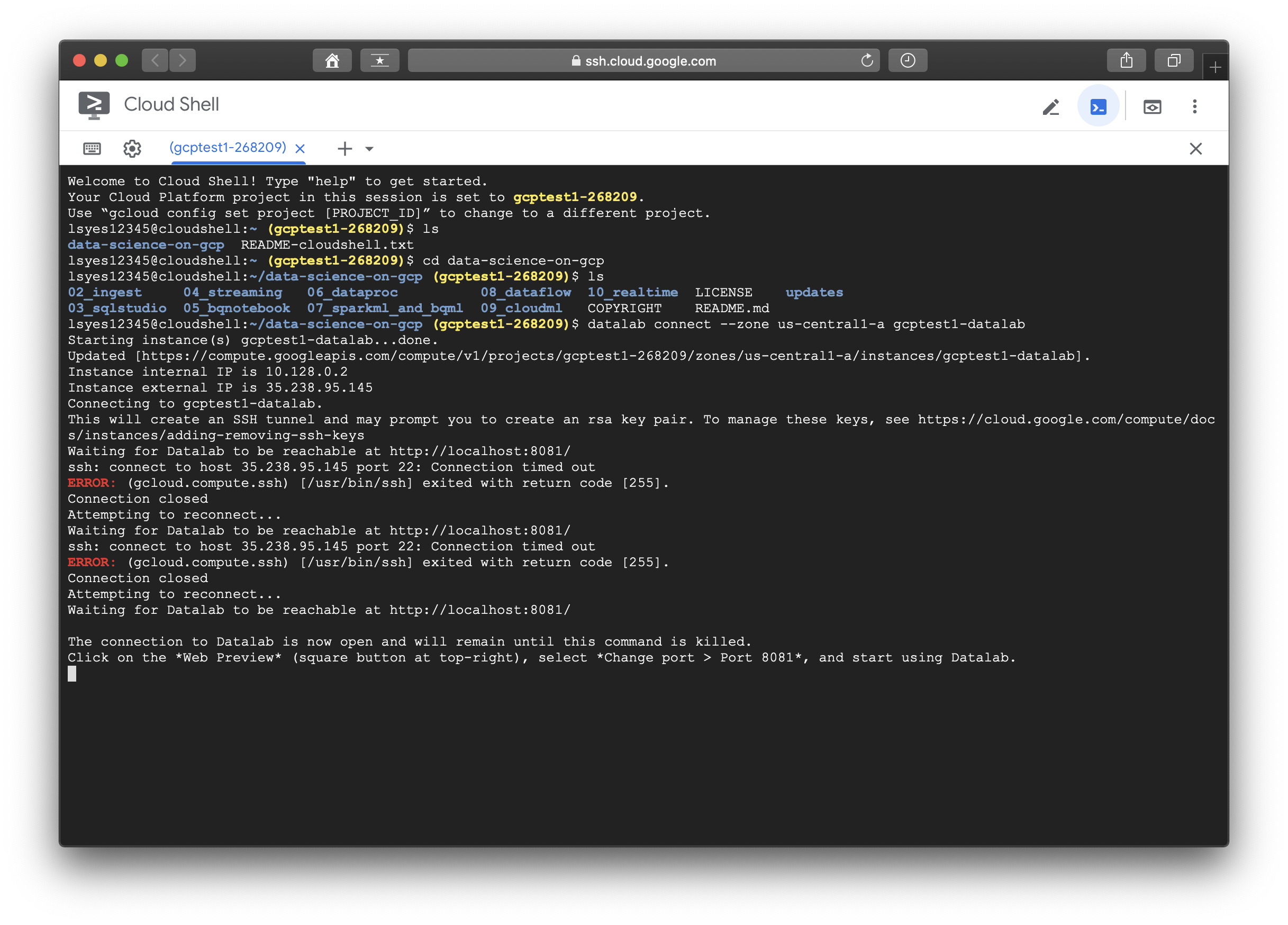
데이터랩에 접속했다면 하나씩 살펴보도록 하자.
1. 주피터 노트북 실행, pwd
!pwd # 노트북이 존재하는 현재 폴더의 경로를 얻는다.
# !는 주피터에게 쉘명령임을 알려주며, %bash는 여러 명령을 실행할 때 사용한다
2. 설치된 패키지 확인
list와 freeze의 차이는 quant의 첫 게시글을 확인하면 알 수 있다.
!pip freeze # 설치된 패키지들을 살펴볼 수 있다.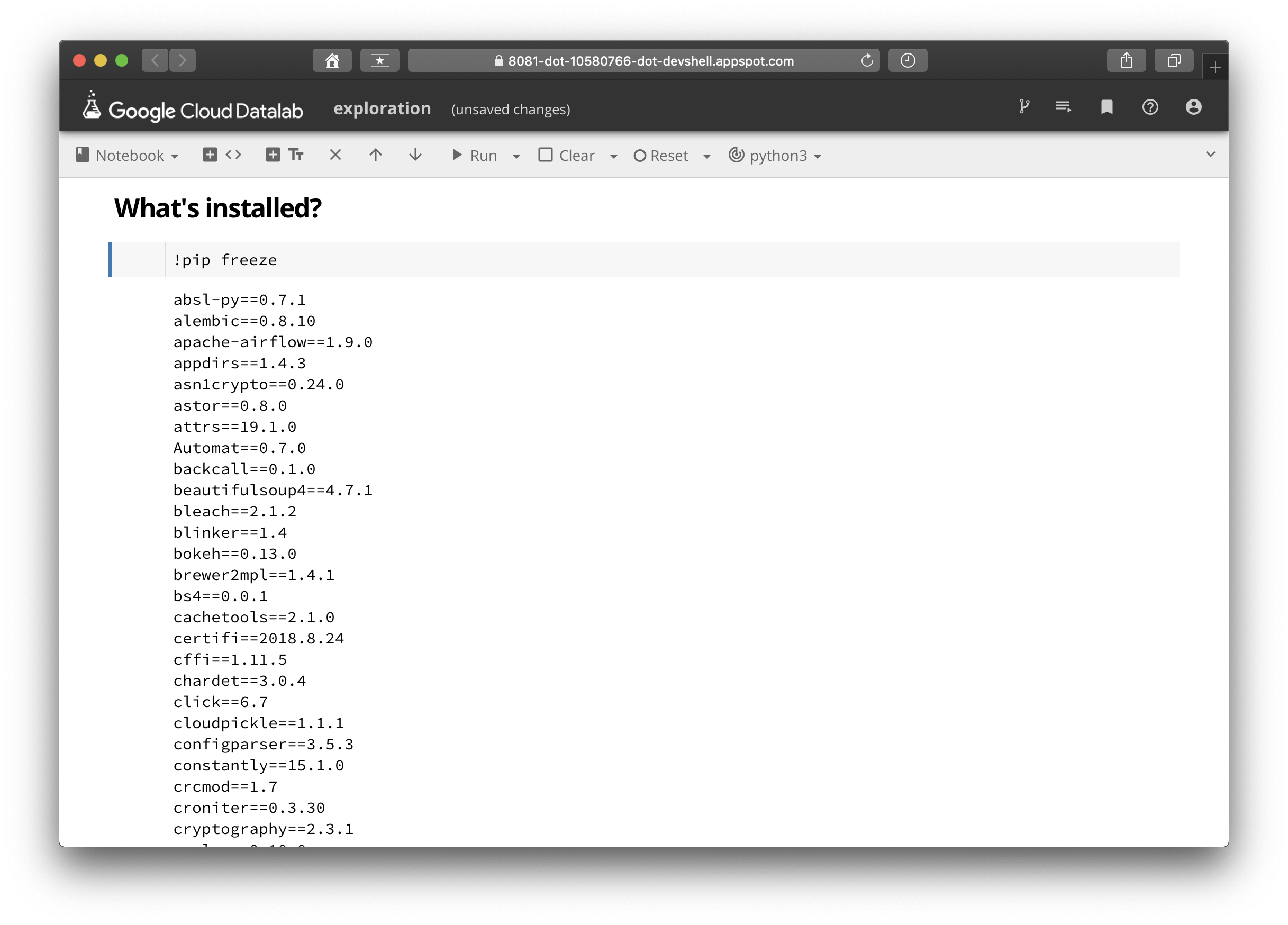
3. bigquery magic
Google Cloud Data-LAB에서는 bigquery magic환경을 사용해서 빅쿼리 테이블의 스키마를 볼 수 있다.
%bigquery schema --table flights.tzcorr # %bigquery 매직을 이용해 빅쿼리 테이블 스키마를 볼 수 있다
4. datalab 라이브러리 이용
이전에 %bigquery를 사용했던 것과 동일한 구현으로, 주피터 매직인 %bigquery가 아닌, 순수 파이썬 라이브러리인 datalab.bigquery패키지를 사용할 수도 있다.
import google.datalab.bigquery as bq # bigquery매직을 이용하지 않고도 사용할 수 있다.
sql = """
SELECT ARR_DELAY, DEP_DELAY
FROM flights.tzcorr
WHERE DEP_DELAY >= 10 AND RAND() < 0.01 # RAND()는 0과 1 사이에 균일하게 분포한 값을 가져오므로,
# 0.01을 기준으로 잡으면 전체의 1%의 데이터를 가져온다는 뜻이다.
"""
df = bq.Query(sql).execute().result().to_dataframe()
df.describe()
5. violinplot
violinplot은 커널 밀도 도표이며 확률분포함수(PDF)의 추정치에 해당한다. 실제로 그래프를 살펴보면, 분포가 10분정도에 최빈값을 보이고 있는데, 주변의 편차는 지연이 작은 값보다 큰 값으로 왜곡되어 있다. boxplot이 아닌 violinplot을 이용한 이유는 데이터가 퍼져있는 분산의 정도를 정확하게 알기 어렵기 때문이다.
sns.set_style("whitegrid") # seaborn theme 지정
ax = sns.violinplot(data=df, x='ARR_DELAY', inner='box', orient='h') # violinplot을 그려준다
6. ontime 칼럼 추가
ontime 칼럼이 10분 이내에 도착했을 경우에 칼럼 값이 true가 되는 것에 유념하자.
import google.datalab.bigquery as bq
sql = """
SELECT ARR_DELAY, DEP_DELAY
FROM flights.tzcorr
WHERE RAND() < 0.001
"""
df = bq.Query(sql).execute().result().to_dataframe()
df.describe()
df['ontime'] = df['DEP_DELAY'] < 10
df[df['ARR_DELAY'] > 0].head()
7. violinplot 2, violinplot 3
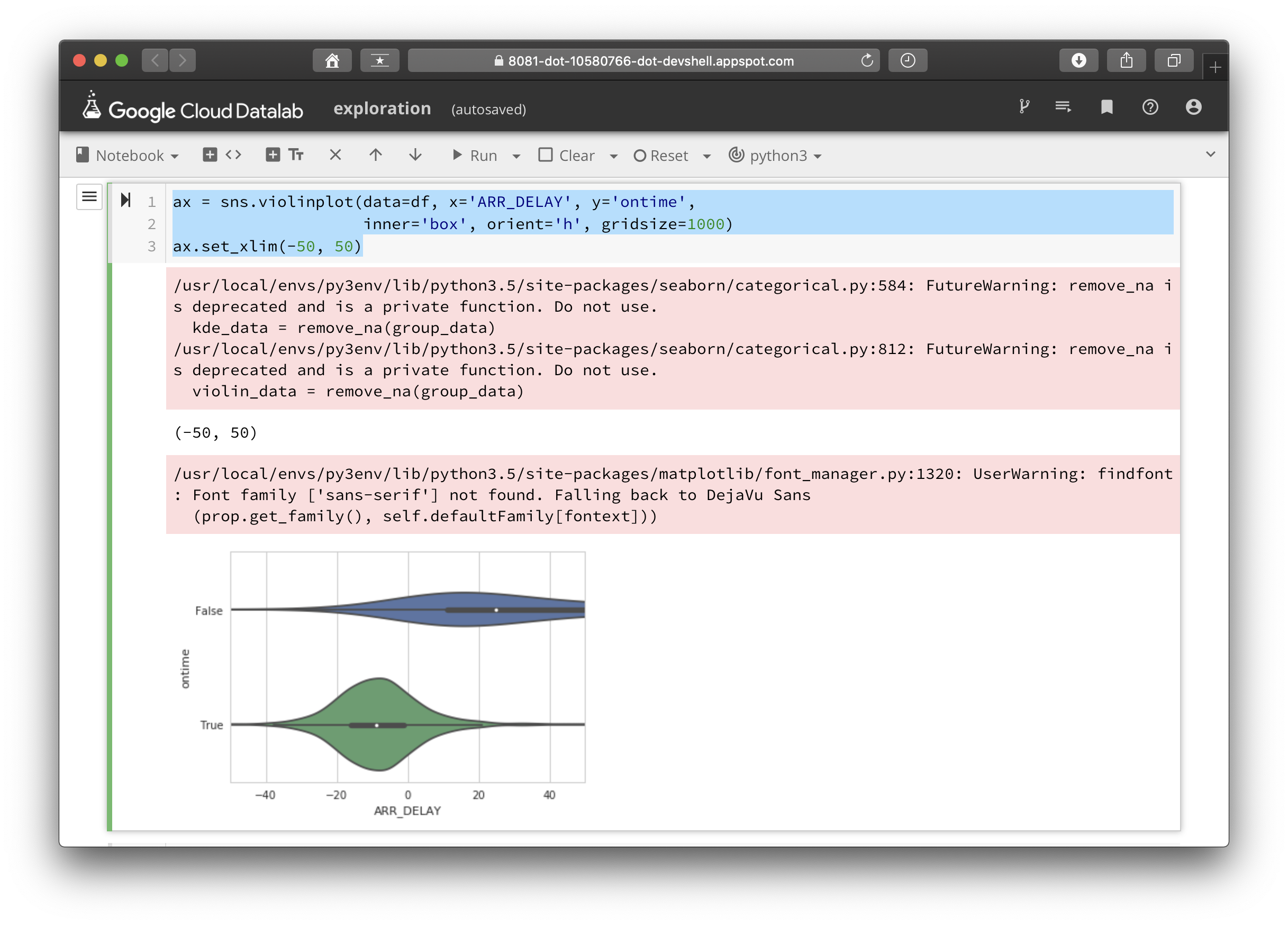
그래프를 그려보면 딱 봐도 10분 이내의 경우 즉, ontime이 true인 경우보다 false인 경우에서 왜곡이 더 심하게 일어나고 있는 것을 직접 확인해 볼 수 있다. 또한 바이올린 도표의 꼬리가 길고 얇게 늘어진 것은 데이터셋의 모델에 문제가 있을 수 있음을 시사한다고 저자는 말하고 있다. 그래프에서 중간값과 3분위값의 위치를 살펴보도록 하자.
import seaborn as sns
sns.set_style("whitegrid")
ax = sns.violinplot(data=df, x='ARR_DELAY', y='ontime', inner='box', orient='h')
ax.set_xlim(-50, 200)
ax = sns.violinplot(data=df, x='ARR_DELAY', y='ontime',
inner='box', orient='h', gridsize=1000)
ax.set_xlim(-50, 50)
이전의 그래프를 좀 더 확대해서 살펴보면 더 정확하게 도표의 상태를 확인할 수 있다. 출발 지연이 10분 이내로 걸렸을 경우에는 대부분의 경우, 그리고 3분위값 까지 도착지연 0분에 들어온다. 최대값은 길게 늘어지고 있다. 또한 출발지연이 10분이 넘어간 경우에는 중간값이 20분을 넘어가고, 3분위 값은 그래프의 도시범위를 넘어서고 있다. 이는 평균에 안좋은 영향을 미칠만한 값들이 있다는 것을 짐작하게 한다.
다음 포스팅에서는 이렇게 violin plot에서 드러난 특이점들을 어떻게 해결할 것인지 알아보도록 하자.
"Data Science on the Google Cloud Platform by Valliappa Lakshmanan (O'Reilly). Copyright 2018 Google Inc."
'[Data Engineering] > [Gloud-GCP]' 카테고리의 다른 글
| [GCP] 6-1. Dataproc cluster, bayes classification (0) | 2020.03.04 |
|---|---|
| [GCP] 5-3. Data refining & model eval (0) | 2020.02.25 |
| [GCP] 5-1. Bigquery, Data Loading (0) | 2020.02.19 |
| [GCP] 4-2. Stream Processing (2) | 2020.02.19 |
| [GCP] 4-1. ETL Pipeline (0) | 2020.02.19 |



