
< 클라우드 데이터 프록 상의 베이즈 분류 >
6장에서 배울 내용은 항공편의 도착지연을 예측하기 위한 베이지안 모델을 생성해서 데이터 과학의 다음 단계를 다루는 일이다. 빅쿼리, 스파크 SQL, 아파치 피그(Apache Pig)를 통합하는 워크플로우로 이를 진행한다. 또한 클라우드 데이터 프록(Cloud Dataproc)을 이용해 지정된 하둡 클러스터를 생성하고, 크기를 조정하고 삭제하는 방법도 배운다.
머신 클러스터에서 대용량 데이터셋은 어떻게 처리할 수 있을까? 책에서는 제프 딘(Jeff Dean)과 산자이 게마왓(Sanjay Ghemawat)의 논문에서 소개된 맵리듀스 방식을 소개하고 있다. 맵리듀스 방식에 대해 알아보자.
- 맵리듀스 -
큰 크기의 문서들이 있고, 이 문서들에서 단어의 빈도를 계산하고 싶다고 가정하자. 맵 리듀스 방식 이전에는 수직확장(머신을 크고 강력한 사양으로 확장시키는 것)이 방법이였다. 문서에 있는 단어가 등장할 때마다 단어 빈도 테이블을 업데이트 하는 것이다. 다음은 이에 대한 의사코드이다.
wordcount(Document[] docs):
wordfrequency = {}
for each document d in docs:
for each word w in d:
wordfrequenct[w] += 1
return wordfrequency 이런 방식으로 구성하면 다중스레드를 구성해서 테이블을 갱신시켜 속도향상을 달성할 수 있지만, 언젠가는 단일 머신의 능력을 초과하는 데이터셋을 처리해야 한다. 따라서 이를 보완하기 위해 머신클러스터들 사이에 문서를 분할시켜 처리가 가능한 수평확장의 개념이 나오게 되었는데 이를 맵리듀스라는 방식으로 구현하는 것이다. 아래는 이를 구현하는 의사코드이다.
# map()함수는 key-value를 처리해 중간값의 key-value를 생성한다.
map(String docname, String content):
for each word w in content:
emitIntermediate(w,1)
# reduce()함수는 동일한 키에 연관된 모든 중간값들을 병합하는 함수이다.
reduce(String word, Iterator<int> intermediate_values):
int result = 0;
for each v in intermediate_values:
result += v;
emit(result);
# framework는 맵과 리듀스 오케스트레이션(Orchestration: 자동관리)을 관리하고, 중간에 group-by-key를 삽입한다.
workcount(Document[] docs):
for each doc in docs:
map(doc.name, doc.content)
group-by-key(key-value-pairs)
for each key in key-values:
reduce(key, intermediate_values)이를 도식화하면 아래의 그림처럼 된다. 맵 리듀스는 맵연산을 하는 컴퓨트 인스턴스가 로컬 파일 시스템 호출로 필요한 데이터에 접근해서, 로컬 시스템에 미리 샤딩된 데이터셋을 분산, 처리하는 알고리즘이다.

- 아파치 하둡 -
하둡은 상용 머신 클러스터에서 어플리케이션의 데이터를 병렬적으로 처리하게 해주는 맵리듀스 알고리즘을 사용해 어플리케이션을 실행하는 프레임워크이다. 아파치 하둡은 프레임워크에 의해 실행되는 맵리듀스 어플리케이션을 작성하는데 필요한 자바 라이브러리를 제공하며, YARN(스케줄러)와 HDFS(분산파일시스템)을 제공한다. 작업실행의 순서는, 먼저 입력 및 출력 파일 위치를 지정한 작업을 프레임워크에 제출하고 맵 및 리듀스 함수를 구현한 일련의 자바클래스를 업로드 하는 순으로 진행된다.
< 실습 - Create Dataproc Cluster >
- 구글 데이터 프록 -
Google Cloud Platform에서는 당연히 하둡 클러스터를 생성하기 위한 명령어를 자원한다. 실습환경에서는 create_cluster.sh 파일에 있으며 실행명령은 다음과 같다.
./create_cluster.sh <BUCKET-NAME> <COMPUTE-ZONE>해당 명령어를 실행시키면.... 역시나 에러가 뜬다. (관련 실습코드들을 분명히 검수를 했을텐데 왜이렇게 에러가 많은지)

문제 해결을 위해 create_cluster.sh파일을 열어보기로 했다.
프로젝트정보는 알아서 불러오고, 버킷정보와 zone만 넘겨주면 된다.
#!/bin/bash
if [ "$#" -ne 2 ]; then
echo "Usage: ./create_cluster.sh bucket-name zone"
exit
fi
PROJECT=$(gcloud config get-value project)
BUCKET=$1
ZONE=$2
INSTALL=gs://$BUCKET/flights/dataproc/install_on_cluster.sh
# upload install file
sed "s/CHANGE_TO_USER_NAME/$USER/g" install_on_cluster.sh > /tmp/install_on_cluster.sh
gsutil cp /tmp/install_on_cluster.sh $INSTALL
# create cluster
gcloud beta dataproc clusters create \
--num-workers=2 \
--scopes=cloud-platform \
--worker-machine-type=n1-standard-4 \
--master-machine-type=n1-standard-4 \
--image-version=1.4 \
--enable-component-gateway \
--optional-components=ANACONDA,JUPYTER \
--zone=$ZONE \
--initialization-actions=$INSTALL \
ch6cluster살펴보니 install file도 있다. 원하는 소프트웨어를 설치하는 스크립트 이다. install_on_cluster.sh인데 이 파일도 마저 열어보도록 하자. ( 실습을 진행할 때는 user name을 변경해주도록 하자 )
#!/bin/bash
# install Google Python client on all nodes
apt-get update
apt-get install -y python-pip
pip install --upgrade google-api-python-client
# git clone on Master
USER=CHANGE_TO_USER_NAME # change this ...
ROLE=$(/usr/share/google/get_metadata_value attributes/dataproc-role)
if [[ "${ROLE}" == 'Master' ]]; then
cd home/$USER
git clone https://github.com/GoogleCloudPlatform/data-science-on-gcp
fi다시 create_cluster.sh파일로 돌아가면, 이 순서 다음에는 이 스크립트를 클라우드 스토리지에 저장하는 부분이 나오며, 그 다음에는 클러스터 생성부분이다. 에러 내용을 확인하면 region부분이 빠져있다고 하고, api승인부분도 처리를 해 주어야 한다. 따라서 create_cluster.sh에 --region us-central1을 추가하고, zone은 us-central1-a로 설정해서 실행시켜 보았다.
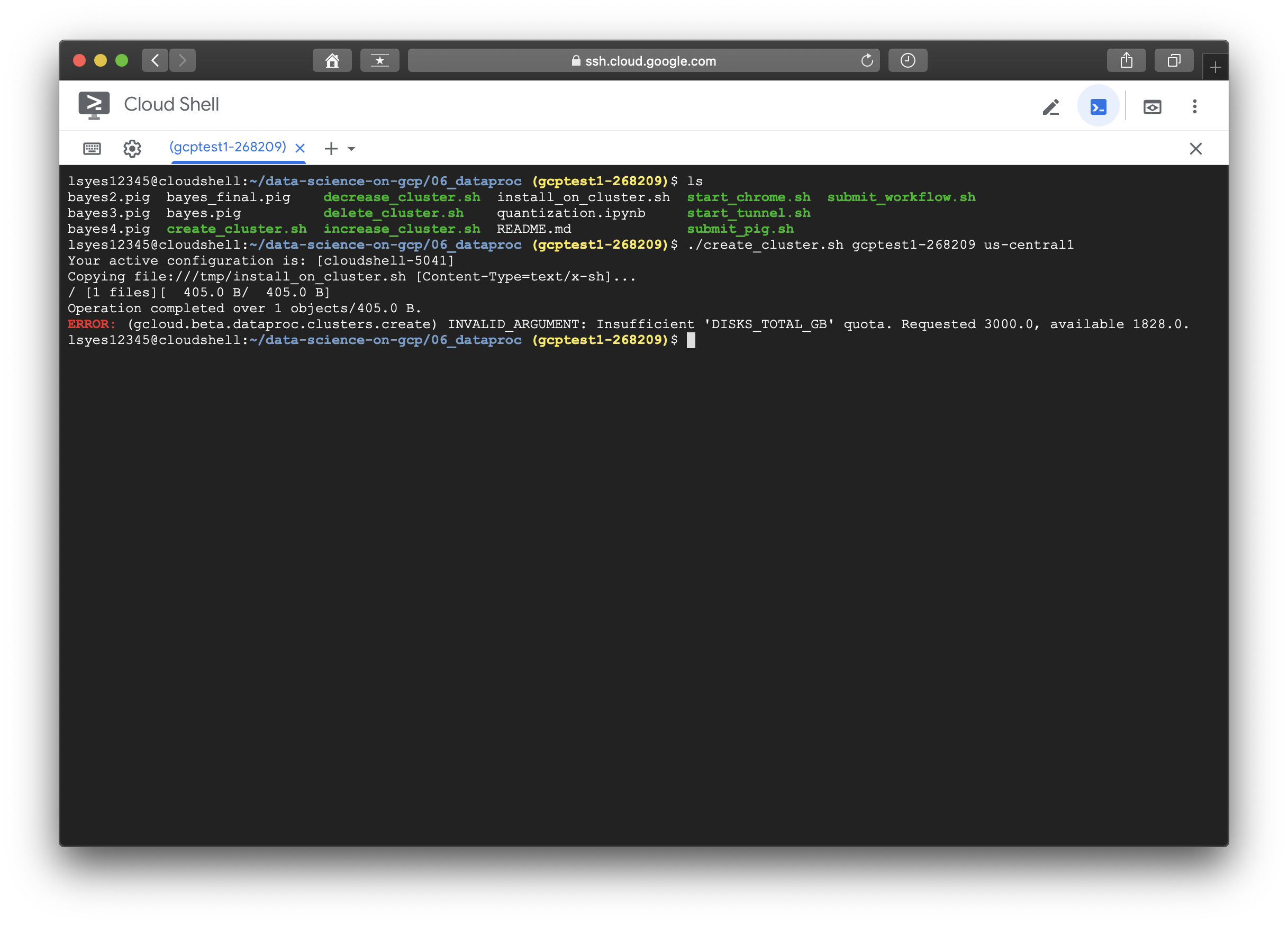
이번엔 IInsufficient 'DISKS_TOTAL_GB' quota 에러가 떴다....... 요구된 것은 3000인데 1828까지 가능하다고 한다. 하,,,,, 그래서 할당량을 변경하려고 IAM에 들어가보니 구글 무료계정(지금 사용중인 300credit 제공)에서는 할당량 확장이 불가능하다고 한다.....(가난한 대학생인데;;;)

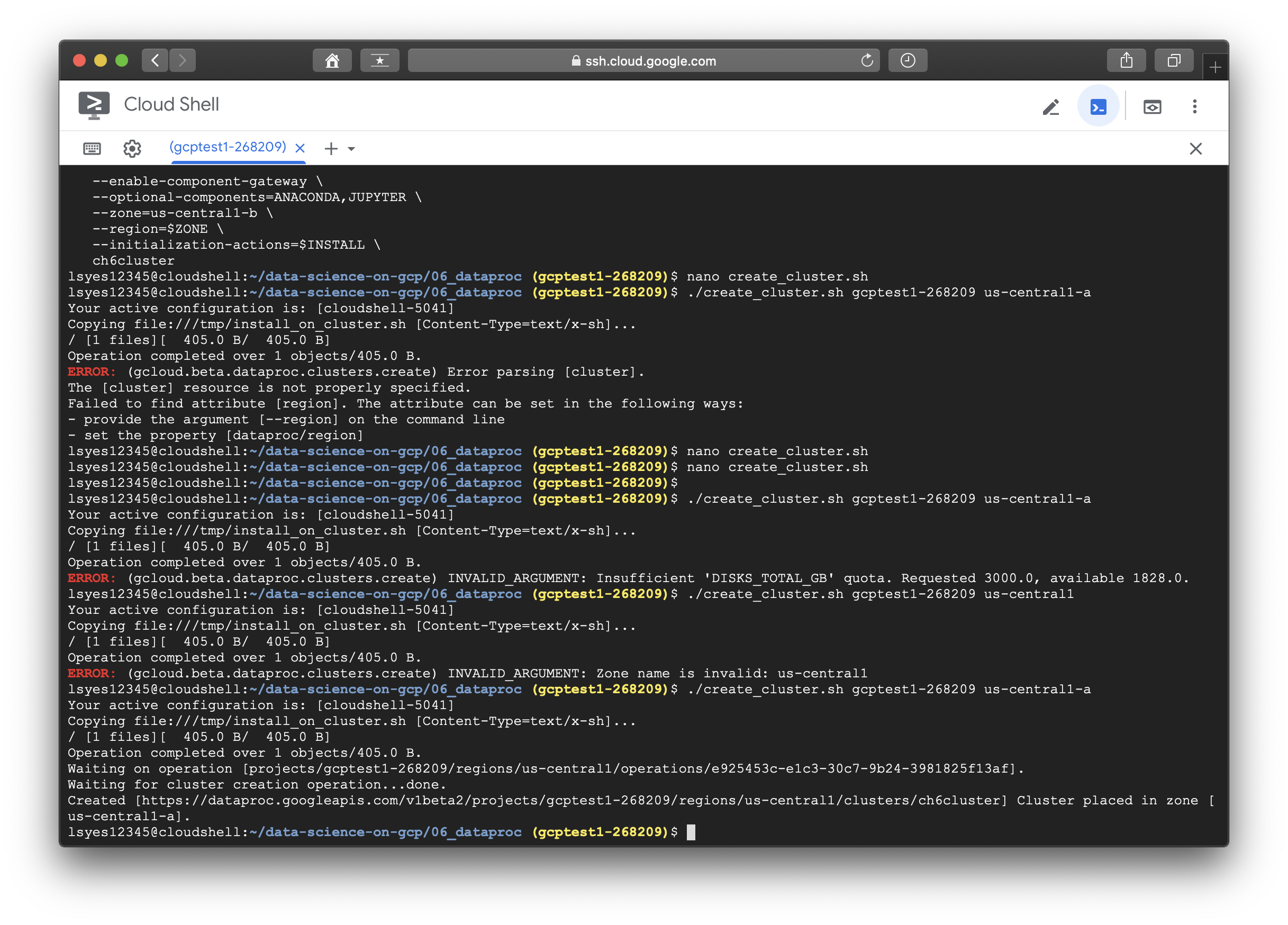
할당량을 보면 최대 한도는 4TB이지만 각 zone별로 나뉘다보니 사용가능한 용량이 3TB가 안되는 것 같았다. 에러내용을 보니 3TB가 필요하고, 현재 가용가능한 용량이 1.8TB이다보니 총 용량을 두배로 늘리면 적절하겠다 싶어, 할당량 증원 요청을 보냈다.

증원 요청은 금방 승인되었다. 요청을 보내고 나니 용량이 잘 늘어난 모습이다. 아래의 모습처럼 cluster 생성도 성공한 모습이다. .....일단 할당량 요청 자체에는 비용이 발생하지 않고, 사용하지 않더라도 여전히 비용은 발생하지 않는다고 한다. 돈 걱정은 덜었으나 이번장도 실습이 매끄럽지는 않을듯 한 예감이 든다;;

< 실습 - Quantization using Spark SQL >
현재까지는 dep_delay라는 하나의 변수만을 사용했다. 하지만 비행하는 시간이 길다면 출발지연때 지체된 시간을 만회할 시간을 벌게 되므로, 이를 만회할 가능성이 더 커지게 된다. 따라서 출발지연과 운행거리를 사용하는 통계모델을 만들어 본다. 이를 위한 양자화를 하는 방법은 도착지연과 운행거리에 따른 확률을 도표에 정리해 보는 것이다. 이렇게 정리하면 큰 값이 어느 빈(bin)에 속한지 알 수 있는데 이런 방식으로 분류하는 것을 베이즈 분류(Bayes classification이라 한다.) 또한 예측변수가 독립적이라면 선택가능한 방법으로 나이브 베이즈 분류(Naive Bayes classification)이 있는데 이는 클러스터를 다루는 현재 실습내용과 거리가 있어 추후에 내용을 보충하도록 하겠다.
해당 섹션을 위한 실습내용을, git에서는 다음과 같이 소개하고 있다.
-
Install the gcloud SDK if you haven't already done so:
-
Create a SSH tunnel to your Dataproc cluster (change the zone appr
gcloud compute ssh --zone=us-central1-a \
--ssh-flag="-D 1080" --ssh-flag="-N" --ssh-flag="-n" \
ch6cluster-m-
Start a new Chrome browser window (you can leave your other Chrome windows running). Specify a non-existent directory (instead of /tmp/junk) and change the path to Chrome appropriately.
rm -rf /tmp/junk /usr/bin/chrome \
--proxy-server="socks5://localhost:1080" \
--host-resolver-rules="MAP * 0.0.0.0 , EXCLUDE localhost" \
--user-data-dir=/tmp/junk-
For example, if you are on Mac OS-X, the path to Chrome is:
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome-
In the new Chrome window, navigate to http://ch6cluster-m:8080/, after making sure to allow outgoing http traffic from your local machine to the Dataproc cluster.
-
In the new browser window, copy-and-paste cells from quantization.ipynb. Make sure to set the appropriate values in the cell containing the PROJECT, BUCKET, and REGION.
-
[optional] make the changes suggested in the notebook to run on the full dataset. Note that you might have to reduce numbers to fit into your quota.
1. 실습 순서에 따라 먼저 gcloud sdk를 설치해보자. MAC OS기준으로 필요한 명령어는 다음과 같다.
curl https://sdk.cloud.google.com | bashexec -l $SHELLgcloud init

2. 로컬 머신에 SSH 터널을 시작한다.
gcloud compute ssh --zone=us-central1-a \
--ssh-flag="-D 1080" --ssh-flag="-N" --ssh-flag="-n" \
ch6cluster-m
3. 다음으로 이 프록시를 위임받을 새로운 크롬 세션을 시작하면 된다. 이를 위한 명령어는 다음과 같다.
rm -rf /tmp/junk
/usr/bin/chrome \
--proxy-server="socks5://localhost:1080" \
--host-resolver-rules="MAP * 0.0.0.0 , EXCLUDE localhost" \
--user-data-dir=/tmp/junk덧붙여 mac 사용자의 경우 chrome 실행파일의 경로는 /Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome 이므로 명령어를 다음과 같이 수정한다.
rm -rf /tmp/junk2
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome \
--proxy-server="socks5://localhost:1080" \
--host-resolver-rules="MAP * 0.0.0.0 , EXCLUDE localhost" \
--user-data-dir=/tmp/junk2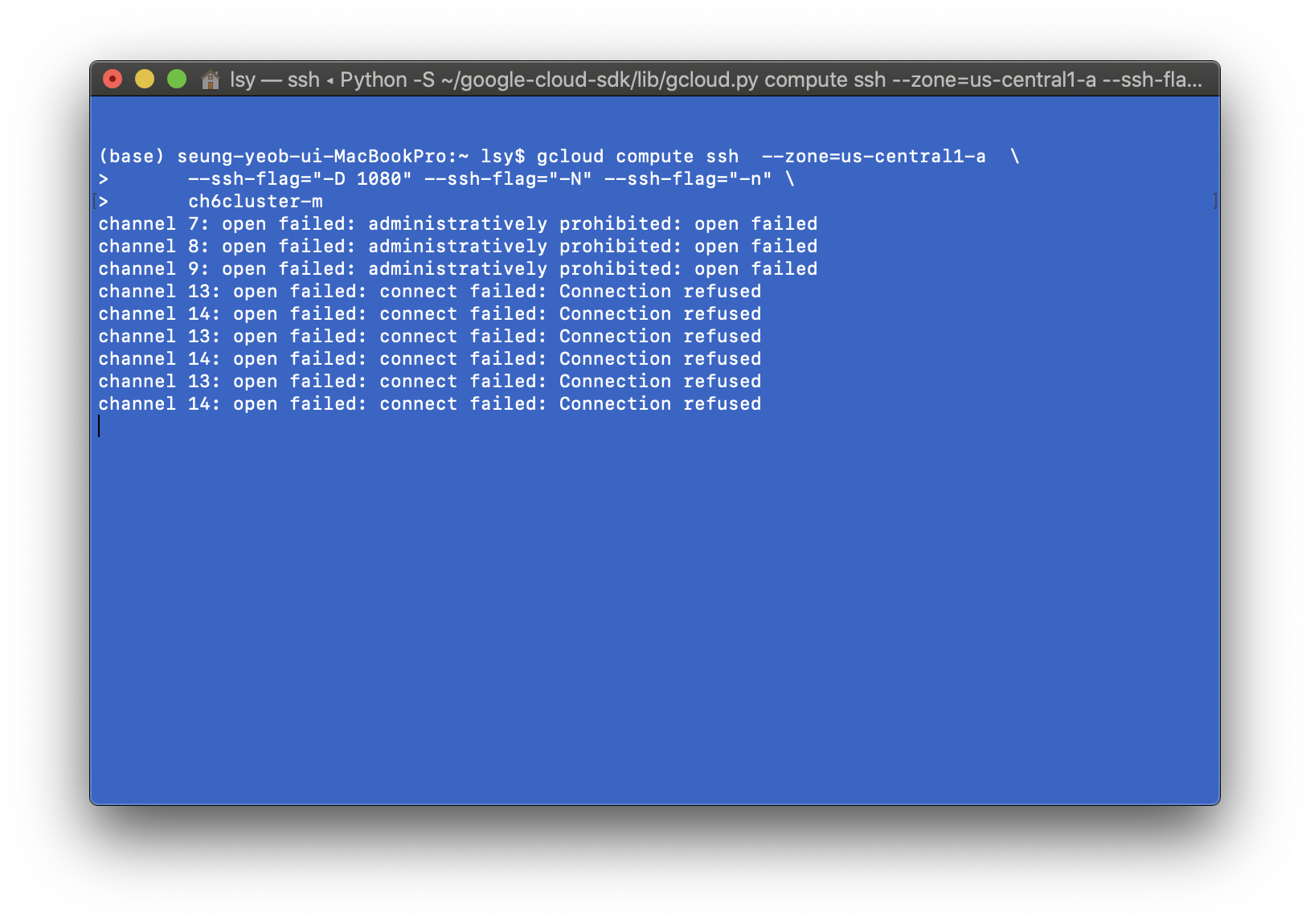

어쩐지 에러 없이 잘 가나 했는데 또다시 문제가 발생했다. socks connection failed라는 문구가 선명히 보인다. 다시 구글링을 통해 문제 해결방법을 찾았다. socks proxcy uncheck이였는데 해당 방법은 다음과 같다.
-
Select Apple > System Preferences.
-
Click Network.
-
Select the network interface you wish to use (i.e. AirPort)
-
Click Advanced.
-
Click Proxies.
-
Select Configure Proxies > Manually (only necessary on Leopard and earlier)
-
Check the box beside SOCKS Proxy.
※ 이 방법으로도 해결되지 않는다면 열리는 크롬창에서 접속하는 주소를 http://ch6cluster-m:8080/ -> 포트번호를 8088로 바꿔서 http://ch6cluster-m:8088/로 접속해보기 바란다.

4. 클라우드 데이터랩에 들어간 다음, ungit아이콘으로 6장의 코드를 포함한 노트북을 클론해준다.

"Data Science on the Google Cloud Platform by Valliappa Lakshmanan (O'Reilly). Copyright 2018 Google Inc."
'[Data Engineering] > [Gloud-GCP]' 카테고리의 다른 글
| [GCP] 6-2. Quantization using Spark SQL (0) | 2020.03.05 |
|---|---|
| [GCP] 5-3. Data refining & model eval (0) | 2020.02.25 |
| [GCP] 5-2. Cloud Data LAB (4) | 2020.02.24 |
| [GCP] 5-1. Bigquery, Data Loading (0) | 2020.02.19 |
| [GCP] 4-2. Stream Processing (2) | 2020.02.19 |



