
< 스트리밍 데이터 송신 및 입수하기 >
3장에 만든 Dash-Board는 부족한 점이 있다. 바로 현재 수행중인 데이터를 반영하지 못하고, 과거의 데이터로만 보여준다는 점이다. 이를 보완하기 위해, 이번장에서는 실시간으로 데이터를 수집하고 이 데이터셋을 데이터베이스로 스트링하는 과정을 실습해 볼 것이다. 먼저 사용할 데이터를 수집하고, 이를 사용할 목적에 맞게 전처리 하는 과정을 거치는데 이를 ETL 파이프라인 단계라고 한다. 이번 장을 공부하면서 느낀점은 데이터 플로우 파이프라인을 구축하는 과정도 과정이고, 실시간으로 데이터를 스트리밍하는 과정도 멋있었지만 무엇보다 관련 데이터를 이토록 세밀하게 분석하고, 발생가능한 오류들을 미리 예상해서 전처리하는 저자의 꼼꼼함에 감탄하지 않을 수 없었다. 마치 관련 업계에 종사해본 것 처럼 시간대와 관련된 데이터들을 각각의 사례에 맞춰 적절히 변환해서 사용하였는데 역시 내 부족함을 절실히 깨닫게 하는 부분이였다. 먼저 전체적인 ETL 파이프라인 단계는 다음과 같다.

이에 맞춰 https://github.com/GoogleCloudPlatform/data-science-on-gcp/tree/master/04_streaming 에 보이는 실습과정에 따라 실습을 따라가보며 관련 코드를 분석해 보도록 하겠다. 실시간 데이터 스트리밍과 처리는 내가 할 프로젝트와도 관련이 밀접하므로 관심있게 뜯어보기로 했다.

※ 이후의 실습과정은 위의 화면에서 보이는 것과 같이 Cloud Shell boost mode를 켜고 진행하자. (안하면 많이 느리다,,,;;;)
- 실습 전 Setup -
먼저 simulate 폴더에 들어가서 관련 패키지들을 설치해주도록 하자. ( install_packages 코드는 다음과 같이 생겼다. )
cd simulate; ./install_packages.sh#!/bin/bash
sudo python3 -m pip install --upgrade timezonefinder pytz 'apache-beam[gcp]'
- df01.py -
그 다음 바로 df01.py (공항데이터 파싱) 파일을 실행시킨다. 실습코드는 df01.py~df06.py까지 있는데 이전에 했던 작업들을 함수화하여 다음 코드에서 겹쳐서 나오는 부분이 많으니 감안하고 필요한 부분만 확인하면 된다.
#!/usr/bin/env python3
# Copyright 2019 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import apache_beam as beam # apache_beam 임포트
import csv
if __name__ == '__main__':
with beam.Pipeline('DirectRunner') as pipeline: # pipeline 기본 옵션
airports = (pipeline
| beam.io.ReadFromText('airports.csv.gz') # 읽어들일 파일을 지정한다.
| beam.Map(lambda line: next(csv.reader([line]))) # 공항 파일을 한줄 단위로 읽는다.
| beam.Map(lambda fields: (fields[0], (fields[21], fields[26]))) # 원하는 필드를 지정한다. ( 공항 고유번호, ( 위도, 경도 ))
)
(airports
| beam.Map(lambda airport_data: '{},{}'.format(airport_data[0], ','.join(airport_data[1])) ) # 튜플 해제하고 원하는 데이터폼인 x,x,x 모양으로 변환
| beam.io.WriteToText('extracted_airports') # 데이터 출력
)
pipeline.run()
- df02.py -
다음 df02.py는 시간대 정보를 추가하는 과정이다. 출력되는 파일은 airport_with_tz-*
./df02.py
head airports_with_tz-00000*
rm airports_with_tz-*#!/usr/bin/env python3
# Copyright 2016 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import apache_beam as beam
import csv
def addtimezone(lat, lon):
try:
import timezonefinder # timezonefinder 활용예시
tf = timezonefinder.TimezoneFinder()
tz = tf.timezone_at(lng=float(lon), lat=float(lat))
if tz is None: # timezone이 없다면 표준시로 timezone 지정
tz = 'UTC'
return (lat, lon, tz)
except ValueError:
return (lat, lon, 'TIMEZONE') # header
if __name__ == '__main__': # df01.py와 동일
with beam.Pipeline('DirectRunner') as pipeline:
airports = (pipeline
| beam.io.ReadFromText('airports.csv.gz')
| beam.Map(lambda line: next(csv.reader([line])))
| beam.Map(lambda fields: (fields[0], addtimezone(fields[21], fields[26])))
)
airports | beam.Map(lambda f: '{},{}'.format(f[0], ','.join(f[1])) )| beam.io.textio.WriteToText('airports_with_tz')
pipeline.run()
- df03.py -
df03.py 는 모든 시간대를 표준시인 UTC로 변환하는 과정이다.
./df03.py
head -3 all_flights-00000*#!/usr/bin/env python3
# Copyright 2016 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import apache_beam as beam
import csv
def addtimezone(lat, lon): # timezone을 추가한다.
try:
import timezonefinder
tf = timezonefinder.TimezoneFinder()
return (lat, lon, tf.timezone_at(lng=float(lon), lat=float(lat)))
#return (lat, lon, 'America/Los_Angeles') # FIXME
except ValueError:
return (lat, lon, 'TIMEZONE') # header
def as_utc(date, hhmm, tzone):
try:
if len(hhmm) > 0 and tzone is not None:
import datetime, pytz
loc_tz = pytz.timezone(tzone)
loc_dt = loc_tz.localize(datetime.datetime.strptime(date,'%Y-%m-%d'), is_dst=False)
# can't just parse hhmm because the data contains 2400 and the like ...
loc_dt += datetime.timedelta(hours=int(hhmm[:2]), minutes=int(hhmm[2:]))
utc_dt = loc_dt.astimezone(pytz.utc)
return utc_dt.strftime('%Y-%m-%d %H:%M:%S')
else:
return '' # empty string corresponds to canceled flights
except ValueError as e:
print('{} {} {}'.format(date, hhmm, tzone))
raise e
def tz_correct(line, airport_timezones):
fields = line.split(',')
if fields[0] != 'FL_DATE' and len(fields) == 27:
# convert all times to UTC
dep_airport_id = fields[6]
arr_airport_id = fields[10]
dep_timezone = airport_timezones[dep_airport_id][2]
arr_timezone = airport_timezones[arr_airport_id][2]
for f in [13, 14, 17]: #crsdeptime, deptime, wheelsoff
fields[f] = as_utc(fields[0], fields[f], dep_timezone)
for f in [18, 20, 21]: #wheelson, crsarrtime, arrtime
fields[f] = as_utc(fields[0], fields[f], arr_timezone)
yield ','.join(fields)
if __name__ == '__main__':
with beam.Pipeline('DirectRunner') as pipeline:
airports = (pipeline
| 'airports:read' >> beam.io.ReadFromText('airports.csv.gz')
| 'airports:fields' >> beam.Map(lambda line: next(csv.reader([line])))
| 'airports:tz' >> beam.Map(lambda fields: (fields[0], addtimezone(fields[21], fields[26])))
)
flights = (pipeline
| 'flights:read' >> beam.io.ReadFromText('201501_part.csv')
| 'flights:tzcorr' >> beam.FlatMap(tz_correct, beam.pvalue.AsDict(airports))
)
flights | beam.io.textio.WriteToText('all_flights')
pipeline.run()
- df04.py + trouble shooting -
다음은 df04.py인데 갑자기 apache_beam module이 없다는 에러가 발생했다. df03까지도 문제가 없었는데 갑자기 에러라니;;;

황당해서 df04.py ( 시간대 보정 tz_correct 추가 )를 까보기로 했다.
./df04.py
head -3 all_flights-00000*
rm all_flights-*
# cat df04.py로 열어본다#!/usr/bin/env python
# Copyright 2016 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import print_function
import apache_beam as beam
import csv
def addtimezone(lat, lon):
try:
import timezonefinder
tf = timezonefinder.TimezoneFinder()
return (lat, lon, tf.timezone_at(lng=float(lon), lat=float(lat)))
#return (lat, lon, 'America/Los_Angeles') # FIXME
except ValueError:
return (lat, lon, 'TIMEZONE') # header
def as_utc(date, hhmm, tzone):
try:
if len(hhmm) > 0 and tzone is not None:
import datetime, pytz
loc_tz = pytz.timezone(tzone)
loc_dt = loc_tz.localize(datetime.datetime.strptime(date,'%Y-%m-%d'), is_dst=False)
# can't just parse hhmm because the data contains 2400 and the like ...
loc_dt += datetime.timedelta(hours=int(hhmm[:2]), minutes=int(hhmm[2:]))
utc_dt = loc_dt.astimezone(pytz.utc)
return utc_dt.strftime('%Y-%m-%d %H:%M:%S'), loc_dt.utcoffset().total_seconds()
else:
return '',0 # empty string corresponds to canceled flights
except ValueError as e:
print('{} {} {}'.format(date, hhmm, tzone))
raise e
def add_24h_if_before(arrtime, deptime):
import datetime
if len(arrtime) > 0 and len(deptime) > 0 and arrtime < deptime:
adt = datetime.datetime.strptime(arrtime, '%Y-%m-%d %H:%M:%S')
adt += datetime.timedelta(hours=24)
return adt.strftime('%Y-%m-%d %H:%M:%S')
else:
return arrtime
def tz_correct(line, airport_timezones):
fields = line.split(',')
if fields[0] != 'FL_DATE' and len(fields) == 27:
# convert all times to UTC
dep_airport_id = fields[6]
arr_airport_id = fields[10]
dep_timezone = airport_timezones[dep_airport_id][2]
arr_timezone = airport_timezones[arr_airport_id][2]
for f in [13, 14, 17]: #crsdeptime, deptime, wheelsoff
fields[f], deptz = as_utc(fields[0], fields[f], dep_timezone)
for f in [18, 20, 21]: #wheelson, crsarrtime, arrtime
fields[f], arrtz = as_utc(fields[0], fields[f], arr_timezone)
for f in [17, 18, 20, 21]:
fields[f] = add_24h_if_before(fields[f], fields[14])
fields.extend(airport_timezones[dep_airport_id])
fields[-1] = str(deptz)
fields.extend(airport_timezones[arr_airport_id])
fields[-1] = str(arrtz)
yield ','.join(fields)
if __name__ == '__main__':
with beam.Pipeline('DirectRunner') as pipeline:
airports = (pipeline
| 'airports:read' >> beam.io.ReadFromText('airports.csv.gz')
| 'airports:fields' >> beam.Map(lambda line: next(csv.reader([line])))
| 'airports:tz' >> beam.Map(lambda fields: (fields[0], addtimezone(fields[21], fields[26])))
)
flights = (pipeline
| 'flights:read' >> beam.io.ReadFromText('201501_part.csv')
| 'flights:tzcorr' >> beam.FlatMap(tz_correct, beam.pvalue.AsDict(airports))
)
flights | beam.io.textio.WriteToText('all_flights')
pipeline.run()
별다른 이상은 없었지만 python2.x에서 3.x로 넘어오면서 __future__module에 의해 충돌이 발생해서 3버전의 apache_beam module을 2.x인 콘솔이 읽어오지 못하는 문제 같았다. 그래서 아래와 같은 방법으로 콘솔이 가리키는 python을 2.7에서 3.7로 변경했다. ( 더 좋은 방법이 있으신 고수분들 댓글 부탁드립니다...ㅠㅠㅠ )
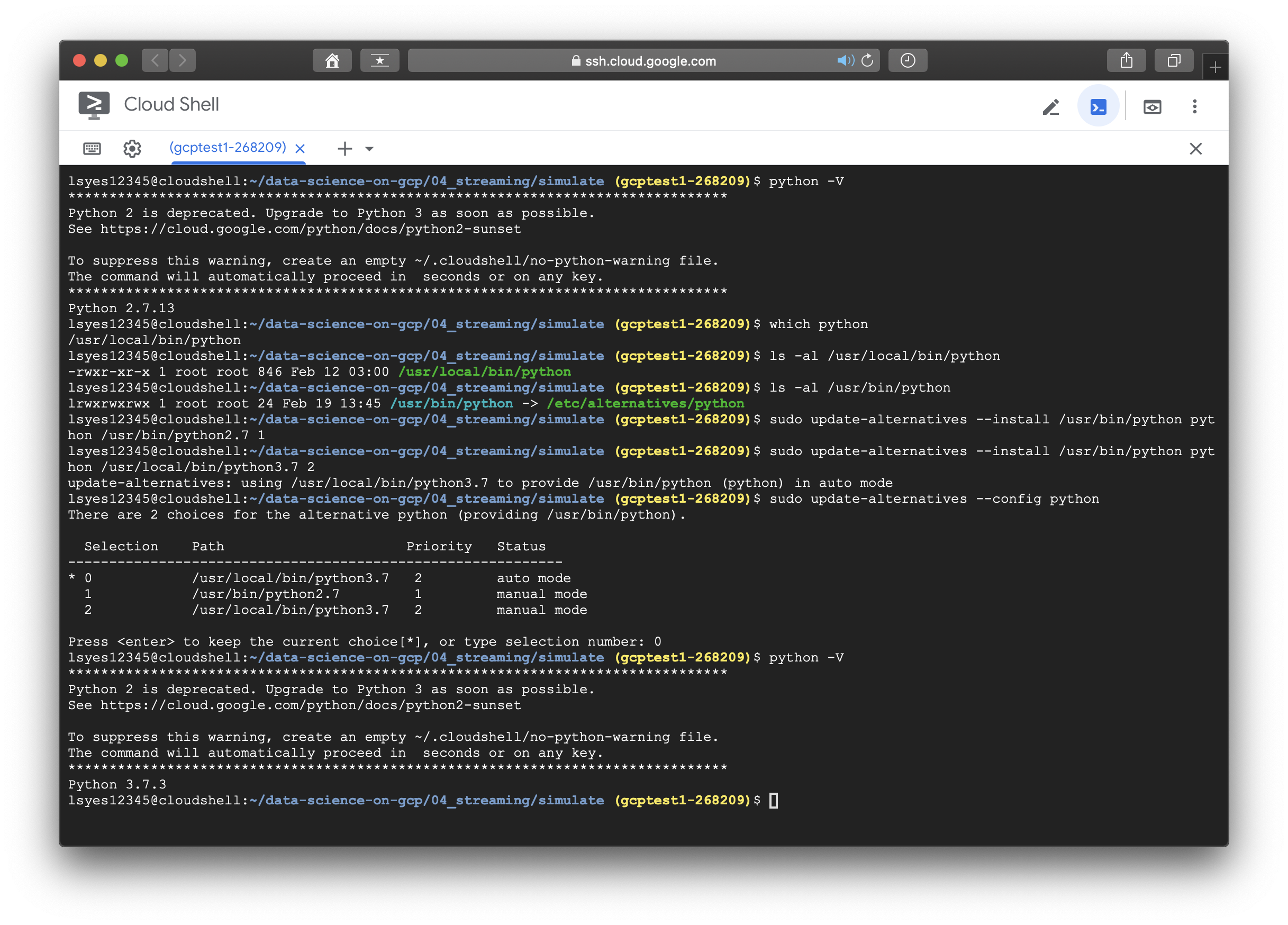
- df05.py -
다음은 이벤트 생성을 위한 df05.py이다.
./df05.py
head -3 all_events-00000*
rm all_events-*#!/usr/bin/env python3
# Copyright 2016 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import apache_beam as beam
import csv
DATETIME_FORMAT='%Y-%m-%dT%H:%M:%S'
def addtimezone(lat, lon):
try:
import timezonefinder
tf = timezonefinder.TimezoneFinder()
return (lat, lon, tf.timezone_at(lng=float(lon), lat=float(lat)))
#return (lat, lon, 'America/Los_Angeles') # FIXME
except ValueError:
return (lat, lon, 'TIMEZONE') # header
def as_utc(date, hhmm, tzone):
try:
if len(hhmm) > 0 and tzone is not None:
import datetime, pytz
loc_tz = pytz.timezone(tzone)
loc_dt = loc_tz.localize(datetime.datetime.strptime(date,'%Y-%m-%d'), is_dst=False)
# can't just parse hhmm because the data contains 2400 and the like ...
loc_dt += datetime.timedelta(hours=int(hhmm[:2]), minutes=int(hhmm[2:]))
utc_dt = loc_dt.astimezone(pytz.utc)
return utc_dt.strftime(DATETIME_FORMAT), loc_dt.utcoffset().total_seconds()
else:
return '',0 # empty string corresponds to canceled flights
except ValueError as e:
print ('{} {} {}'.format(date, hhmm, tzone))
raise e
def add_24h_if_before(arrtime, deptime):
import datetime
if len(arrtime) > 0 and len(deptime) > 0 and (arrtime < deptime):
adt = datetime.datetime.strptime(arrtime, DATETIME_FORMAT)
adt += datetime.timedelta(hours=24)
return adt.strftime(DATETIME_FORMAT)
else:
return arrtime
def tz_correct(line, airport_timezones):
fields = line.split(',')
if fields[0] != 'FL_DATE' and len(fields) == 27:
# convert all times to UTC
dep_airport_id = fields[6]
arr_airport_id = fields[10]
dep_timezone = airport_timezones[dep_airport_id][2]
arr_timezone = airport_timezones[arr_airport_id][2]
for f in [13, 14, 17]: #crsdeptime, deptime, wheelsoff
fields[f], deptz = as_utc(fields[0], fields[f], dep_timezone)
for f in [18, 20, 21]: #wheelson, crsarrtime, arrtime
fields[f], arrtz = as_utc(fields[0], fields[f], arr_timezone)
for f in [17, 18, 20, 21]:
fields[f] = add_24h_if_before(fields[f], fields[14])
fields.extend(airport_timezones[dep_airport_id])
fields[-1] = str(deptz)
fields.extend(airport_timezones[arr_airport_id])
fields[-1] = str(arrtz)
yield fields
def get_next_event(fields):
if len(fields[14]) > 0:
event = list(fields) # copy
event.extend(['departed', fields[14]])
for f in [16,17,18,19,21,22,25]:
event[f] = '' # not knowable at departure time
yield event
if len(fields[21]) > 0:
event = list(fields)
event.extend(['arrived', fields[21]])
yield event
def run():
with beam.Pipeline('DirectRunner') as pipeline:
airports = (pipeline
| 'airports:read' >> beam.io.ReadFromText('airports.csv.gz')
| 'airports:fields' >> beam.Map(lambda line: next(csv.reader([line])))
| 'airports:tz' >> beam.Map(lambda fields: (fields[0], addtimezone(fields[21], fields[26])))
)
flights = (pipeline
| 'flights:read' >> beam.io.ReadFromText('201501_part.csv')
| 'flights:tzcorr' >> beam.FlatMap(tz_correct, beam.pvalue.AsDict(airports))
)
(flights
| 'flights:tostring' >> beam.Map(lambda fields: ','.join(fields))
| 'flights:out' >> beam.io.textio.WriteToText('all_flights')
)
events = flights | beam.FlatMap(get_next_event)
(events
| 'events:tostring' >> beam.Map(lambda fields: ','.join(fields))
| 'events:out' >> beam.io.textio.WriteToText('all_events')
)
pipeline.run()
if __name__ == '__main__':
run()
- df06.py + api enable, bucket load -
마지막 df06.py를 하기 이전에 먼저 GCP Web Console에서 Dataflow API를 enable 시켜주도록 하자.




이후에 Cloud Shell에서 flights라는 BigQuery를 하나 생성하고, Bucket에 airports.csv.gz파일을 업로드한다. ( BigQuery를 다루는 정확한 과정과 이유는 5장에서 설명할 예정이다.) 그 다음 df06.py를 실행시키도록 한다.
bq mk flights
gsutil cp airports.csv.gz gs://<BUCKET-NAME>/flights/airports/airports.csv.gz
./df06.py -p $DEVSHELL_PROJECT_ID -b <BUCKETNAME> #!/usr/bin/env python3
# Copyright 2016 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import apache_beam as beam
import csv
DATETIME_FORMAT='%Y-%m-%dT%H:%M:%S'
def addtimezone(lat, lon):
try:
import timezonefinder
tf = timezonefinder.TimezoneFinder()
return (lat, lon, tf.timezone_at(lng=float(lon), lat=float(lat)))
#return (lat, lon, 'America/Los_Angeles') # FIXME
except ValueError:
return (lat, lon, 'TIMEZONE') # header
def as_utc(date, hhmm, tzone):
try:
if len(hhmm) > 0 and tzone is not None:
import datetime, pytz
loc_tz = pytz.timezone(tzone)
loc_dt = loc_tz.localize(datetime.datetime.strptime(date,'%Y-%m-%d'), is_dst=False)
# can't just parse hhmm because the data contains 2400 and the like ...
loc_dt += datetime.timedelta(hours=int(hhmm[:2]), minutes=int(hhmm[2:]))
utc_dt = loc_dt.astimezone(pytz.utc)
return utc_dt.strftime(DATETIME_FORMAT), loc_dt.utcoffset().total_seconds()
else:
return '',0 # empty string corresponds to canceled flights
except ValueError as e:
print ('{} {} {}'.format(date, hhmm, tzone))
raise e
def add_24h_if_before(arrtime, deptime):
import datetime
if len(arrtime) > 0 and len(deptime) > 0 and (arrtime < deptime):
adt = datetime.datetime.strptime(arrtime, DATETIME_FORMAT)
adt += datetime.timedelta(hours=24)
return adt.strftime(DATETIME_FORMAT)
else:
return arrtime
def tz_correct(line, airport_timezones_dict):
def airport_timezone(airport_id):
if airport_id in airport_timezones_dict:
return airport_timezones_dict[airport_id]
else:
return ('37.52', '-92.17', u'America/Chicago') # population center of US
fields = line.split(',')
if fields[0] != 'FL_DATE' and len(fields) == 27:
# convert all times to UTC
dep_airport_id = fields[6]
arr_airport_id = fields[10]
dep_timezone = airport_timezone(dep_airport_id)[2]
arr_timezone = airport_timezone(arr_airport_id)[2]
for f in [13, 14, 17]: #crsdeptime, deptime, wheelsoff
fields[f], deptz = as_utc(fields[0], fields[f], dep_timezone)
for f in [18, 20, 21]: #wheelson, crsarrtime, arrtime
fields[f], arrtz = as_utc(fields[0], fields[f], arr_timezone)
for f in [17, 18, 20, 21]:
fields[f] = add_24h_if_before(fields[f], fields[14])
fields.extend(airport_timezone(dep_airport_id))
fields[-1] = str(deptz)
fields.extend(airport_timezone(arr_airport_id))
fields[-1] = str(arrtz)
yield fields
def get_next_event(fields):
if len(fields[14]) > 0:
event = list(fields) # copy
event.extend(['departed', fields[14]])
for f in [16,17,18,19,21,22,25]:
event[f] = '' # not knowable at departure time
yield event
if len(fields[17]) > 0:
event = list(fields) # copy
event.extend(['wheelsoff', fields[17]])
for f in [18,19,21,22,25]:
event[f] = '' # not knowable at wheelsoff time
yield event
if len(fields[21]) > 0:
event = list(fields)
event.extend(['arrived', fields[21]])
yield event
def create_row(fields):
header = 'FL_DATE,UNIQUE_CARRIER,AIRLINE_ID,CARRIER,FL_NUM,ORIGIN_AIRPORT_ID,ORIGIN_AIRPORT_SEQ_ID,ORIGIN_CITY_MARKET_ID,ORIGIN,DEST_AIRPORT_ID,DEST_AIRPORT_SEQ_ID,DEST_CITY_MARKET_ID,DEST,CRS_DEP_TIME,DEP_TIME,DEP_DELAY,TAXI_OUT,WHEELS_OFF,WHEELS_ON,TAXI_IN,CRS_ARR_TIME,ARR_TIME,ARR_DELAY,CANCELLED,CANCELLATION_CODE,DIVERTED,DISTANCE,DEP_AIRPORT_LAT,DEP_AIRPORT_LON,DEP_AIRPORT_TZOFFSET,ARR_AIRPORT_LAT,ARR_AIRPORT_LON,ARR_AIRPORT_TZOFFSET,EVENT,NOTIFY_TIME'.split(',')
featdict = {}
for name, value in zip(header, fields):
featdict[name] = value
featdict['EVENT_DATA'] = ','.join(fields)
return featdict
def run(project, bucket, dataset):
argv = [
'--project={0}'.format(project),
'--job_name=ch04timecorr',
'--save_main_session',
'--staging_location=gs://{0}/flights/staging/'.format(bucket),
'--temp_location=gs://{0}/flights/temp/'.format(bucket),
'--setup_file=./setup.py',
'--max_num_workers=8',
'--autoscaling_algorithm=THROUGHPUT_BASED',
'--runner=DataflowRunner'
]
airports_filename = 'gs://{}/flights/airports/airports.csv.gz'.format(bucket)
flights_raw_files = 'gs://{}/flights/raw/*.csv'.format(bucket)
flights_output = 'gs://{}/flights/tzcorr/all_flights'.format(bucket)
events_output = '{}:{}.simevents'.format(project, dataset)
pipeline = beam.Pipeline(argv=argv)
airports = (pipeline
| 'airports:read' >> beam.io.ReadFromText(airports_filename)
| 'airports:fields' >> beam.Map(lambda line: next(csv.reader([line])))
| 'airports:tz' >> beam.Map(lambda fields: (fields[0], addtimezone(fields[21], fields[26])))
)
flights = (pipeline
| 'flights:read' >> beam.io.ReadFromText (flights_raw_files)
| 'flights:tzcorr' >> beam.FlatMap(tz_correct, beam.pvalue.AsDict(airports))
)
(flights
| 'flights:tostring' >> beam.Map(lambda fields: ','.join(fields))
| 'flights:out' >> beam.io.textio.WriteToText(flights_output)
)
events = flights | beam.FlatMap(get_next_event)
schema = 'FL_DATE:date,UNIQUE_CARRIER:string,AIRLINE_ID:string,CARRIER:string,FL_NUM:string,ORIGIN_AIRPORT_ID:string,ORIGIN_AIRPORT_SEQ_ID:integer,ORIGIN_CITY_MARKET_ID:string,ORIGIN:string,DEST_AIRPORT_ID:string,DEST_AIRPORT_SEQ_ID:integer,DEST_CITY_MARKET_ID:string,DEST:string,CRS_DEP_TIME:timestamp,DEP_TIME:timestamp,DEP_DELAY:float,TAXI_OUT:float,WHEELS_OFF:timestamp,WHEELS_ON:timestamp,TAXI_IN:float,CRS_ARR_TIME:timestamp,ARR_TIME:timestamp,ARR_DELAY:float,CANCELLED:string,CANCELLATION_CODE:string,DIVERTED:string,DISTANCE:float,DEP_AIRPORT_LAT:float,DEP_AIRPORT_LON:float,DEP_AIRPORT_TZOFFSET:float,ARR_AIRPORT_LAT:float,ARR_AIRPORT_LON:float,ARR_AIRPORT_TZOFFSET:float,EVENT:string,NOTIFY_TIME:timestamp,EVENT_DATA:string'
(events
| 'events:totablerow' >> beam.Map(lambda fields: create_row(fields))
| 'events:out' >> beam.io.WriteToBigQuery(
events_output, schema=schema,
write_disposition=beam.io.BigQueryDisposition.WRITE_TRUNCATE,
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED)
)
pipeline.run()
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser(description='Run pipeline on the cloud')
parser.add_argument('-p','--project', help='Unique project ID', required=True)
parser.add_argument('-b','--bucket', help='Bucket where your data were ingested in Chapter 2', required=True)
parser.add_argument('-d','--dataset', help='BigQuery dataset', default='flights')
args = vars(parser.parse_args())
print ("Correcting timestamps and writing to BigQuery dataset {}".format(args['dataset']))
run(project=args['project'], bucket=args['bucket'], dataset=args['dataset'])
그 다음 GCP web console로 가서 Dataflow 작업이 완료되기를 기다리자. 작업이 완료되면 BigQuery 내부에 테이블이 생성되고 SQL문을 실행시켜 볼 수 있다.

- ETL Pipeline 결과 -

얼마간의 인내의 시간을 거치면 Dataflow 작업이 완료된 모습을 볼 수 있다. 이후에 BigQuery에 들어가서 SQL문을 실행시켜보면 다음과 같은 결과값을 얻어낼 수 있다.

"Data Science on the Google Cloud Platform by Valliappa Lakshmanan (O'Reilly). Copyright 2018 Google Inc."
'[Data Engineering] > [Gloud-GCP]' 카테고리의 다른 글
| [GCP] 5-1. Bigquery, Data Loading (0) | 2020.02.19 |
|---|---|
| [GCP] 4-2. Stream Processing (2) | 2020.02.19 |
| [GCP] 3-3. DashBoard (0) | 2020.02.18 |
| [GCP] 3-2. Decision Model (0) | 2020.02.18 |
| [GCP] 3-1. How to make Dataset (0) | 2020.02.18 |



