
< 사용할 Data-set 살펴보기 >
비행 도착시간이 15분 지연될 가능성을 알아보려면 모델링을 해야하고, 이를 위해서는 과거의 수많은 항공편에 대한 데이터들이 필요하다. 미 교통 통계국(BTS)에서는 이에 필요한 항공데이터를 충실히 제공하고 있다. 이유는 항공편이 정시에 운행되는지 감시하고, 항공사들이 책무에 충실하게끔 하려는 목적이라고 한다;;
아무튼 미 교통 통계국(https://www.bts.gov/topics/airlines-and-airports/airline-information-download)에서는 미국의 모든 주요 항공사들의 통계자료를 '레이블'로 제공하고 있다. BTS에 수집된 데이터들은 매우 상세하고 신뢰할만 하며 데이터 수집 표준을 작성할 때 모델로서 사용할 만 하다. 항공사들은 매월 이 특별한 데이터들을 보고하고, BTS에서는 이 데이터들을 합쳐 웹에 무료로 제공하고 있다.

이번 장을 공부하면서 느낀점은 데이터를 정리하는 규칙이 굉장히 세분화되어 있고, 자세하다는 것이다. 귀찮아서 대충 넘어갈 수 있는 부분도 세분화하고 모든 파티션과 필드 구분에는 그에 해당하는 이유가 있었다. 또한 상황에 따라 발생할 수 있는 오차를 잘 정의하고 있는데, 훈련-제공간 왜곡(training-serving skew)가 그러했다. 이 훈련과 제공간의 왜곡을 최소화시키는 방향으로 시스템을 구성하는 것이 목표이다.

원본 데이터셋에서는 다음과 같이 27개의 데이터 필드를 제공한다. 이는 책에 포함된 깃 레퍼지토리에서 제공하는 2015년도의 데이터셋을 기준으로 도시한 것이며 현 시점인 2020년도의 데이터셋을 기준으로 코드를 실행시켜보기 위해서는 필드가 일부 수정되었으니 이를 적용해보면 된다.
ex)
FL_DATE,OP_UNIQUE_CARRIER,OP_CARRIER_AIRLINE_ID,OP_CARRIER,OP_CARRIER_FL_NUM,ORIGIN_AIRPORT_ID,ORIGIN_AIRPORT_SEQ_ID,ORIGIN_CITY_MARKET_ID,ORIGIN,DEST_AIRPORT_ID,DEST_AIRPORT_SEQ_ID,DEST_CITY_MARKET_ID,DEST,CRS_DEP_TIME,DEP_TIME,DEP_DELAY,WHEELS_ON,TAXI_IN,CRS_ARR_TIME,ARR_TIME,ARR_DELAY,CANCELLED,CANCELLATION_CODE,DIVERTED
< 실습 - 정적(고정된) Data 스케줄링 >
실습은 저자가 제공하는 깃 레퍼지토리의 예제소스를 다운받는것에서부터 시작한다. Google Cloud Platform에서 클라우드 쉘을 실행시킨다. 그리고 해당 쉘에 제공되는 깃허브 레퍼지토리를 클론시킨다.
폴더를 이동해서 chapt 2인 02_ingest폴더로 들어간다. (이후에 이루어지는 모든 실습은 쉘 스크립트로 이루어지며, 관련된 중요소스중 일부를 기록에 남기도록 하겠다
그 이후에 data 디렉토리로 이동해서 02_ingest폴더 내에 있는 쉘스크립트를 실행시킨다.(이후 이런 간단한 커맨드는 생략하기로 한다.)
> mkdir data
> cd data
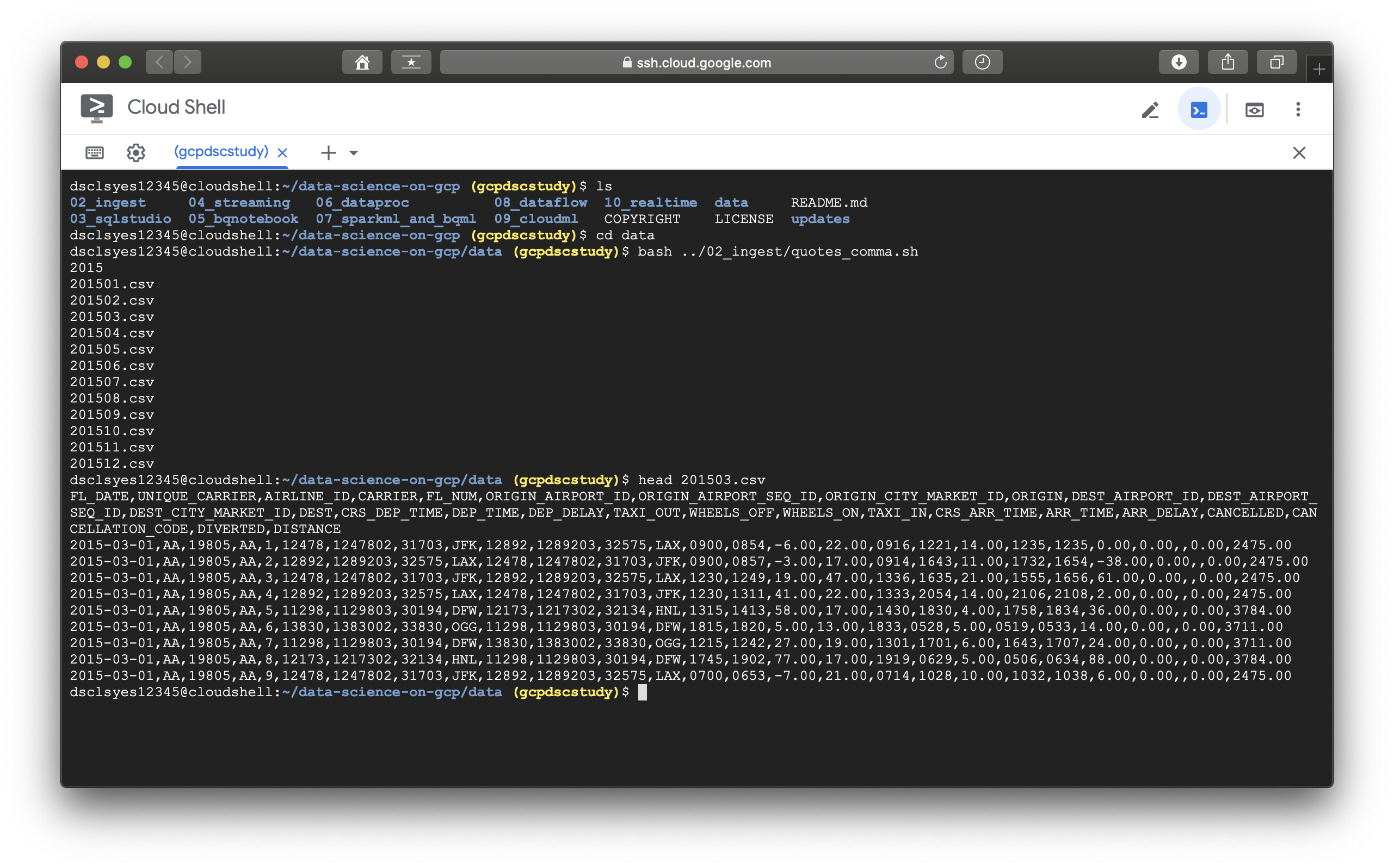
> bash ../02_ingest/download.sh
bash 명령어로 download.sh를 실행시키면 아래의 모습과 같이 데이터들이 Cloud Shell 내부로 저장된다.

데이터들이 전부 다운로드되었다면 실제 사용에 앞서 값들을 전처리하는 과정을 거친다. ( 스크린 샷에 해당 내용들은 생략하였다. )
전처리과정이 종료되면 관련 데이터들을 생성해놓은 버킷에 추가한다.

데이터를 gsutil 명령어로 직접 버킷에 넣을 수도 있지만 저자의 깃 레퍼지토리에서 제공하는 쉘스크립트로도 관련 데이터들을 업로드 할 수 있다.

< 실습 - 주기적인 데이터 스케줄링 >
지금까지는 저장된 압축데이터를 풀고, csv파일에서 원하는 데이터를 가져와 전처리를 한 뒤, 버킷에 올리는 과정을 살펴보았다. 하지만 이는 고정된 데이터였다. 월 주기로 데이터를 다운로드, 스케줄링하는 방법을 소개한다. 책에서 처음으로 소개하는 기본적인 방법(권장하지 않는 방법)은 유닉스/리눅스에 크론(cron)작업을 거는 것이다. 이는 crontab file에
1 2 10 * * /etc/bin/ingest_flights.py
를 추가하는 것이다. 위의 코드가 추가되면 매달 10일 02:01에 시스템이 ingest_flights.py를 구동시킨다. 하지만 이와 같은 방법은 복원력과 신뢰성에 여러 악영향을 준다. 책에서는 ingest_flights.py라는 파이썬 코드를 포함한 로직으로 이 문제를 해결하였는데 먼저 ingest_flights라는 코드를 확인한 이후에 다음 설명을 이어나가도록 하겠다.
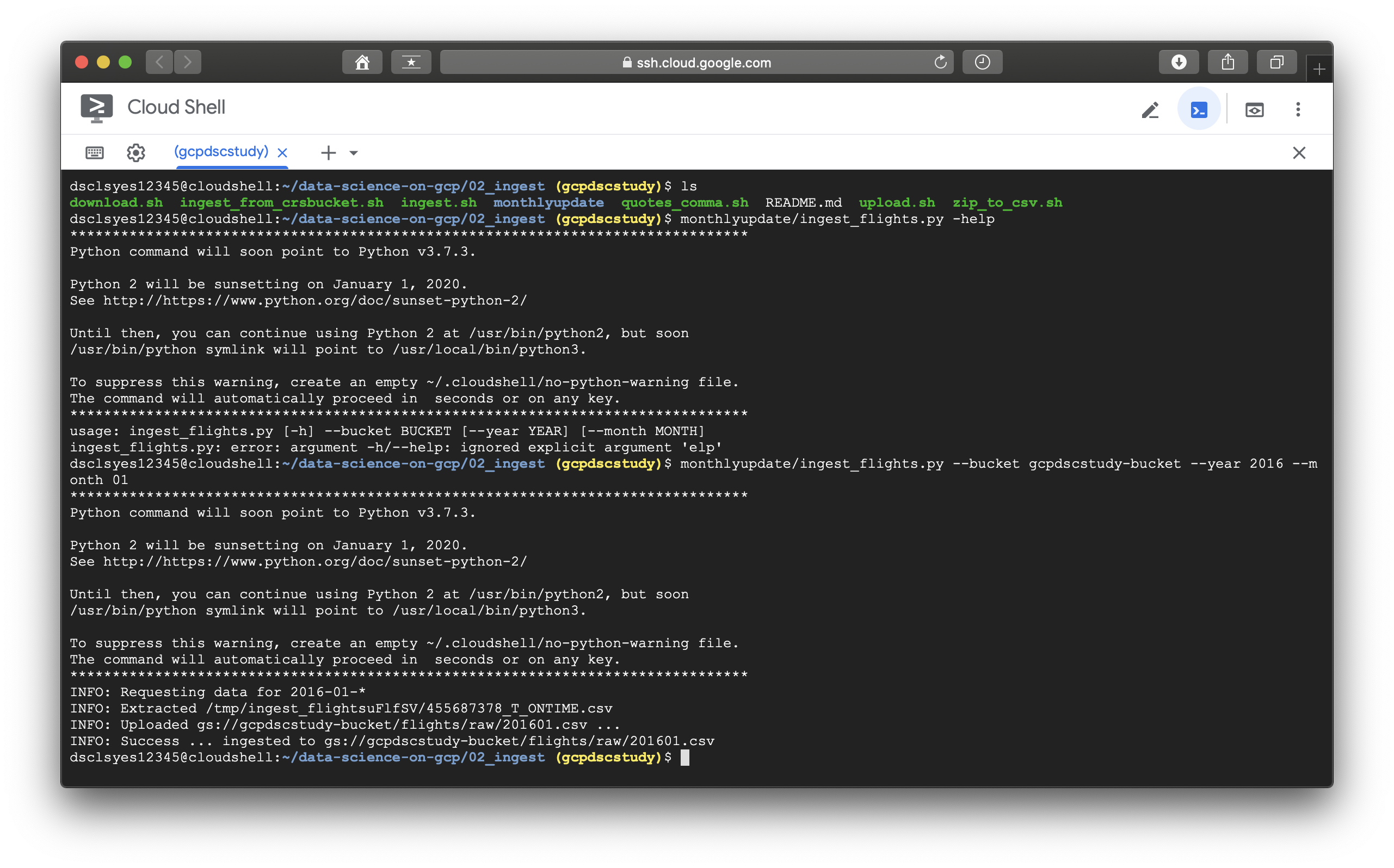
to be continued
"Data Science on the Google Cloud Platform by Valliappa Lakshmanan (O'Reilly). Copyright 2018 Google Inc."
'[Data Engineering] > [Gloud-GCP]' 카테고리의 다른 글
| [GCP] 3-3. DashBoard (0) | 2020.02.18 |
|---|---|
| [GCP] 3-2. Decision Model (0) | 2020.02.18 |
| [GCP] 3-1. How to make Dataset (0) | 2020.02.18 |
| [GCP] 2-2. Periodic scheduling, flask web application (0) | 2020.02.18 |
| [GCP] 1. Introduction (4) | 2020.02.18 |



