
< 실습 - 주기적인 데이터 스케줄링, 이어서 ... >
아래에 보이는 코드는 ingest_flights.py의 전체 코드이다. 2장의 실습에 핵심적인 내용을 포함하고 있으며, 관련 주석으로 부족한 코드 설명을 보완함을 밝힌다. (일일이 코드를 분석,설명해주는 것은 이 포스팅의 목적이 아니다.) 이어서 나오는 사진은 Cloud-Shell에서 ingest_flights.py를 실행시킨 모습이다.
< ingest_flights.py code 전문 >
#!/usr/bin/env python
# Copyright 2016 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import shutil
import logging
import os.path
import zipfile
import datetime
import tempfile
from google.cloud import storage
from google.cloud.storage import Blob
try:
from urllib.request import urlopen as impl
# For Python 3.0 and later
def urlopen(url, data):
return impl(url, data.encode('utf-8'))
def remove_quote(text):
return text.translate(str.maketrans('','', '"'))
except ImportError as error:
# Fall back to Python 2's urllib2
from urllib2 import urlopen
def remove_quote(text):
return text.translate(None, '"')
def download(YEAR, MONTH, destdir): #bash script가 하드코딩된 연도(2015)에서 데이터를 가져오는데에 비해, python코드는 연도와 월을 입력값으로 받는다.
'''
Downloads on-time performance data and returns local filename
YEAR e.g.'2015'
MONTH e.g. '01 for January
'''
logging.info('Requesting data for {}-{}-*'.format(YEAR, MONTH))
PARAMS=" <파라미터 생략>".format(YEAR, MONTH)
url='https://www.transtats.bts.gov/DownLoad_Table.asp?Table_ID=236&Has_Group=3&Is_Zipped=0' # 이 URL이 나오게 된 이유는 (보완1)에 밝힌다.
filename = os.path.join(destdir, "{}{}.zip".format(YEAR, MONTH))
with open(filename, "wb") as fp:
response = urlopen(url, PARAMS)
fp.write(response.read())
logging.debug("{} saved".format(filename))
return filename
def zip_to_csv(filename, destdir): # 압축해제 후 csv파일을 추출한다.
zip_ref = zipfile.ZipFile(filename, 'r')
cwd = os.getcwd() # 현재 자신의 디렉토리를 반환해준다
os.chdir(destdir) # 현재 디렉터리의 위치를 변경한다.
zip_ref.extractall() # 현재 디렉터리에 내용물을 전부 압축해제한다.
os.chdir(cwd) # 원래 디렉터리로 돌아간다.
csvfile = os.path.join(destdir, zip_ref.namelist()[0]) # 경로를 병합하여 새 경로를 만든다. 압축 파일의 모든 멤버 리스트중 첫번째 값과 병합
zip_ref.close()
logging.info("Extracted {}".format(csvfile))
return csvfile
class DataUnavailable(Exception):
def __init__(self, message):
self.message = message
class UnexpectedFormat(Exception):
def __init__(self, message):
self.message = message
def verify_ingest(csvfile): # 책에서는 ingest data를 확인하는 코드도 추가해 놓았다. 추가한 두가지 내용은 다음과 같다.
# 1) 다운받은 코드가 한줄 이상인지를 확인한다.
# 2) csv파일이 정확한 헤더를 가지고 있는지를 확인한다.
#확인하려하는 헤더는 다음과 같다.
expected_header = 'FL_DATE,UNIQUE_CARRIER,AIRLINE_ID,CARRIER,FL_NUM,ORIGIN_AIRPORT_ID,ORIGIN_AIRPORT_SEQ_ID,ORIGIN_CITY_MARKET_ID,ORIGIN,DEST_AIRPORT_ID,DEST_AIRPORT_SEQ_ID,DEST_CITY_MARKET_ID,DEST,CRS_DEP_TIME,DEP_TIME,DEP_DELAY,TAXI_OUT,WHEELS_OFF,WHEELS_ON,TAXI_IN,CRS_ARR_TIME,ARR_TIME,ARR_DELAY,CANCELLED,CANCELLATION_CODE,DIVERTED,DISTANCE'
with open(csvfile, 'r') as csvfp: # close하는 실수를 줄여주는 중요한 coding style
firstline = csvfp.readline().strip() # .strip()함수는 문자열이 있을 때 양쪽 끝에 있는 공백과 \n기호를 삭제시켜준다.
if (firstline != expected_header): # 첫라인의 헤더가 예상한 헤더가 아닐 경우에 (내용 2)에 해당 )
os.remove(csvfile)
msg = 'Got header={}, but expected={}'.format(
firstline, expected_header)
logging.error(msg)
raise UnexpectedFormat(msg)
if next(csvfp, None) == None: # 다음요소인 내부 데이터가 한줄 이상인지 확인 (내용 1)에 해당 )
os.remove(csvfile)
msg = ('Received a file from BTS that has only the header and no content')
raise DataUnavailable(msg)
def remove_quotes_comma(csvfile, year, month): # 따옴표와 줄 끝의 쉼표를 제거하는 코드
'''
returns output_csv_file or raises DataUnavailable exception
'''
try:
outfile = os.path.join(os.path.dirname(csvfile),
'{}{}.csv'.format(year, month))
with open(csvfile, 'r') as infp: # close 필요없이 블럭 벗어나면 자동으로 close
with open(outfile, 'w') as outfp: # 마찬가지.
for line in infp:
outline = line.rstrip().rstrip(',') # 따옴표와 줄 끝의 쉼표를 제거할 수 있다.
outline = remove_quote(outline) # quote는 none으로 translate, (line38참조)
outfp.write(outline) # 처리 끝난 내용 작성
outfp.write('\n') # 마감 줄처리 이어서 작성
logging.debug('Ingested {} ...'.format(outfile))
return outfile
finally:
logging.debug("... removing {}".format(csvfile))
os.remove(csvfile)
def upload(csvfile, bucketname, blobname): # 주어진 월의 csv파일을 클라우드 스토리지에 업로드한다.
client = storage.Client()
bucket = client.get_bucket(bucketname)
blob = Blob(blobname, bucket) # blob은 간접객체이다. 간접객체에 대한 설명은 (보완2)에 밝힌다.
blob.upload_from_filename(csvfile)
gcslocation = 'gs://{}/{}'.format(bucketname, blobname) # 이전 부분과 동일. 이하생략.
logging.info('Uploaded {} ...'.format(gcslocation))
return gcslocation
def ingest(year, month, bucket):
'''
ingest flights data from BTS website to Google Cloud Storage
return cloud-storage-blob-name on success.
raises DataUnavailable if this data is not on BTS website
'''
tempdir = tempfile.mkdtemp(prefix='ingest_flights') # mkdtemp()는 임시 디렉토리를 생성한다.
try:
zipfile = download(year, month, tempdir) # download(상단 정의) 호출
bts_csv = zip_to_csv(zipfile, tempdir) # zip_to_csv(상단 정의) 호출
csvfile = remove_quotes_comma(bts_csv, year, month) # remove_quotes_comma(상단 정의) 호출
verify_ingest(csvfile) # 동일
gcsloc = 'flights/raw/{}'.format(os.path.basename(csvfile))
return upload(csvfile, bucket, gcsloc)
finally:
logging.debug('Cleaning up by removing {}'.format(tempdir))
shutil.rmtree(tempdir) # 생성했던 임시 디렉토리 제거
def next_month(bucketname):
'''
Finds which months are on GCS, and returns next year,month to download
'''
client = storage.Client()
bucket = client.get_bucket(bucketname) # bucket 객체 생성
blobs = list(bucket.list_blobs(prefix='flights/raw/')) # blob
files = [blob.name for blob in blobs if 'csv' in blob.name] # csv files only
lastfile = os.path.basename(files[-1]) # 예시-> 201503.csv
logging.debug('The latest file on GCS is {}'.format(lastfile))
year = lastfile[:4] # 2015
month = lastfile[4:6] # 03
return compute_next_month(year, month)
def compute_next_month(year, month): # 다음달을 계산하기위한 함수
dt = datetime.datetime(int(year), int(month), 15) # 15th of month
dt = dt + datetime.timedelta(30) # will always go to next month 이 방법으로 28일~31일 월 전부 커버가능하다.
logging.debug('The next month is {}'.format(dt))
return '{}'.format(dt.year), '{:02d}'.format(dt.month)
if __name__ == '__main__':
import argparse # 인자값을 받아 기능을 수행하게 해주는 모듈
parser = argparse.ArgumentParser(description='ingest flights data from BTS website to Google Cloud Storage')
parser.add_argument('--bucket', help='GCS bucket to upload data to', required=True)
parser.add_argument('--year', help='Example: 2015. If not provided, defaults to getting next month')
parser.add_argument('--month', help='Specify 01 for January. If not provided, defaults to getting next month')
try:
logging.basicConfig(format='%(levelname)s: %(message)s', level=logging.INFO) # 로깅 포맷 변경
args = parser.parse_args()
if args.year is None or args.month is None:
year, month = next_month(args.bucket)
else:
year = args.year
month = args.month
logging.debug('Ingesting year={} month={}'.format(year, month))
gcsfile = ingest(year, month, args.bucket)
logging.info('Success ... ingested to {}'.format(gcsfile))
except DataUnavailable as e:
logging.info('Try again later: {}'.format(e.message))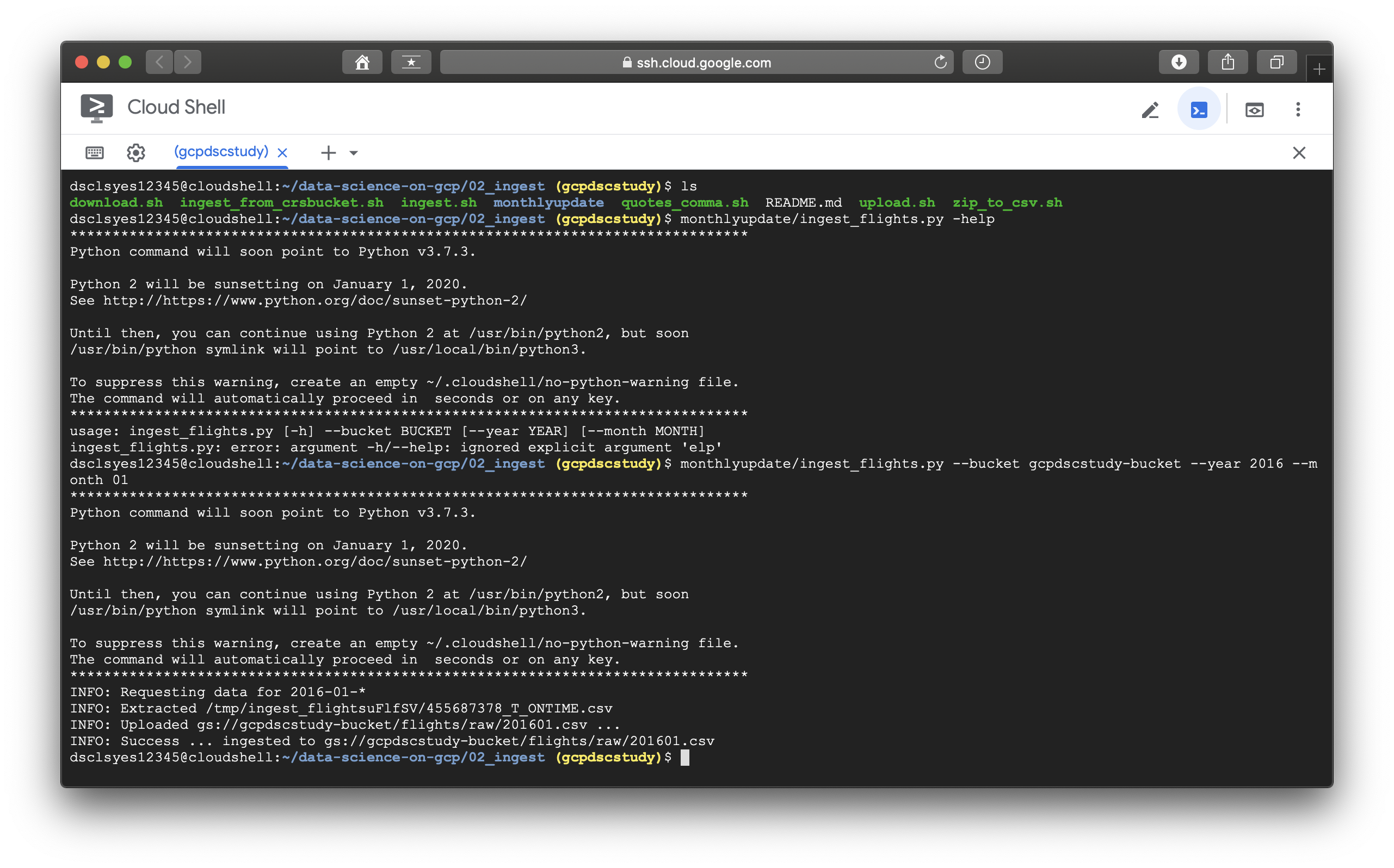
ingest_flights.py는 클라우드 스토리지 버킷을 한달에 한 번 업데이트하는 기능을 가진 Data 입수 프로그램이다. 이번에는 이를 서버리스 방식으로 동작할 수 있는 cron 호출형 flask-web-application을 적용시켜본다.
< 실습 - Flask Web Application (optional) >
flask-web-application을 실행시켜보려고 책에 나온 대로 02_ingest에 들어가 init_appengine.sh를 실행시키려고 했는데..
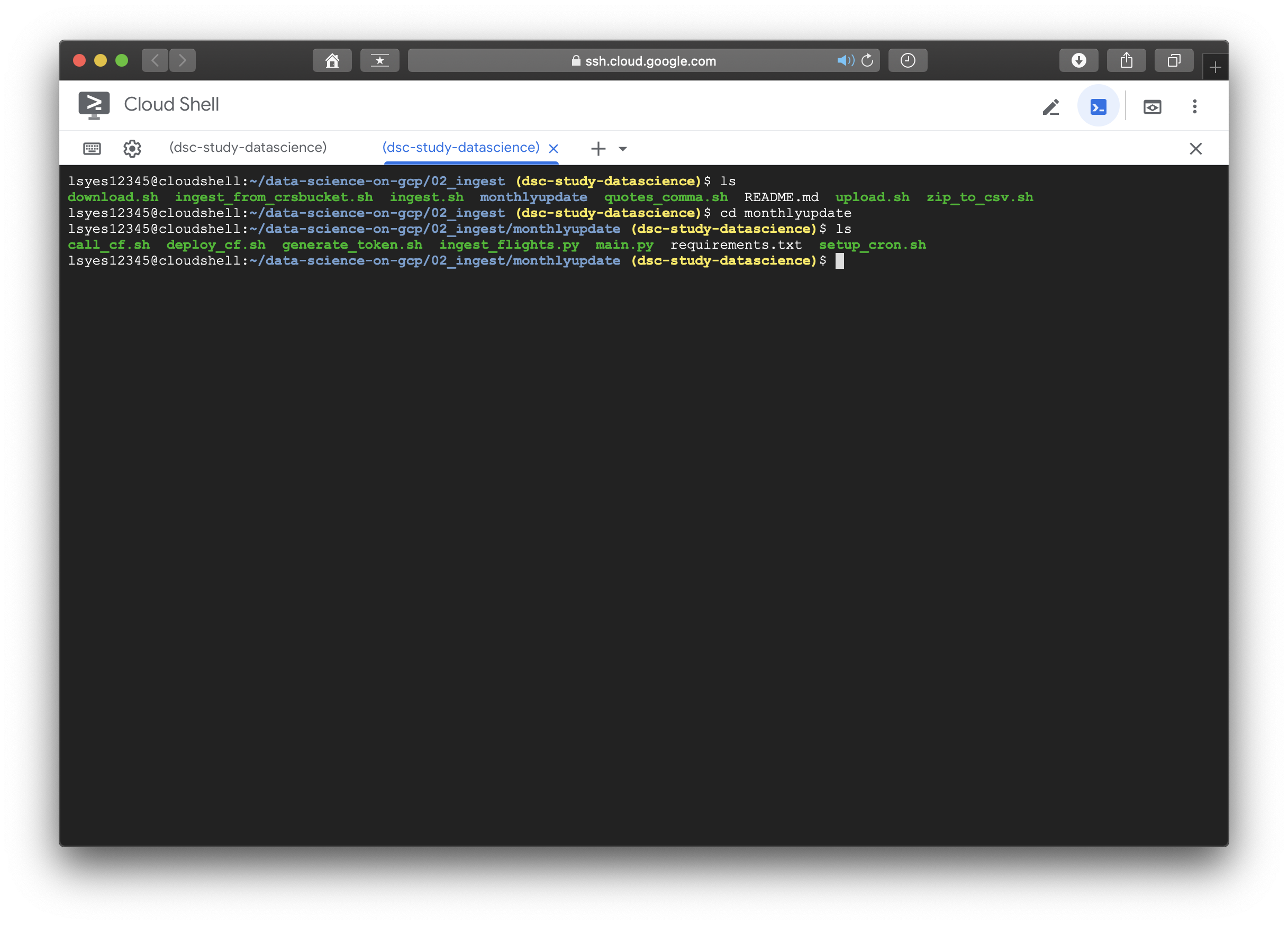
appengine.sh 파일이 없다??? 그 외에 token generate와 setup_cron등의 실행과 관련한 파일들이 눈에 보여서 다 까보았지만 실행순서가 명확하지 않았고 책에 관련 내용이 없어 처음에 꽤나 당황했었다. 잠시 방황하다가 저자를 믿고 readme를 읽어보기로 하였다.
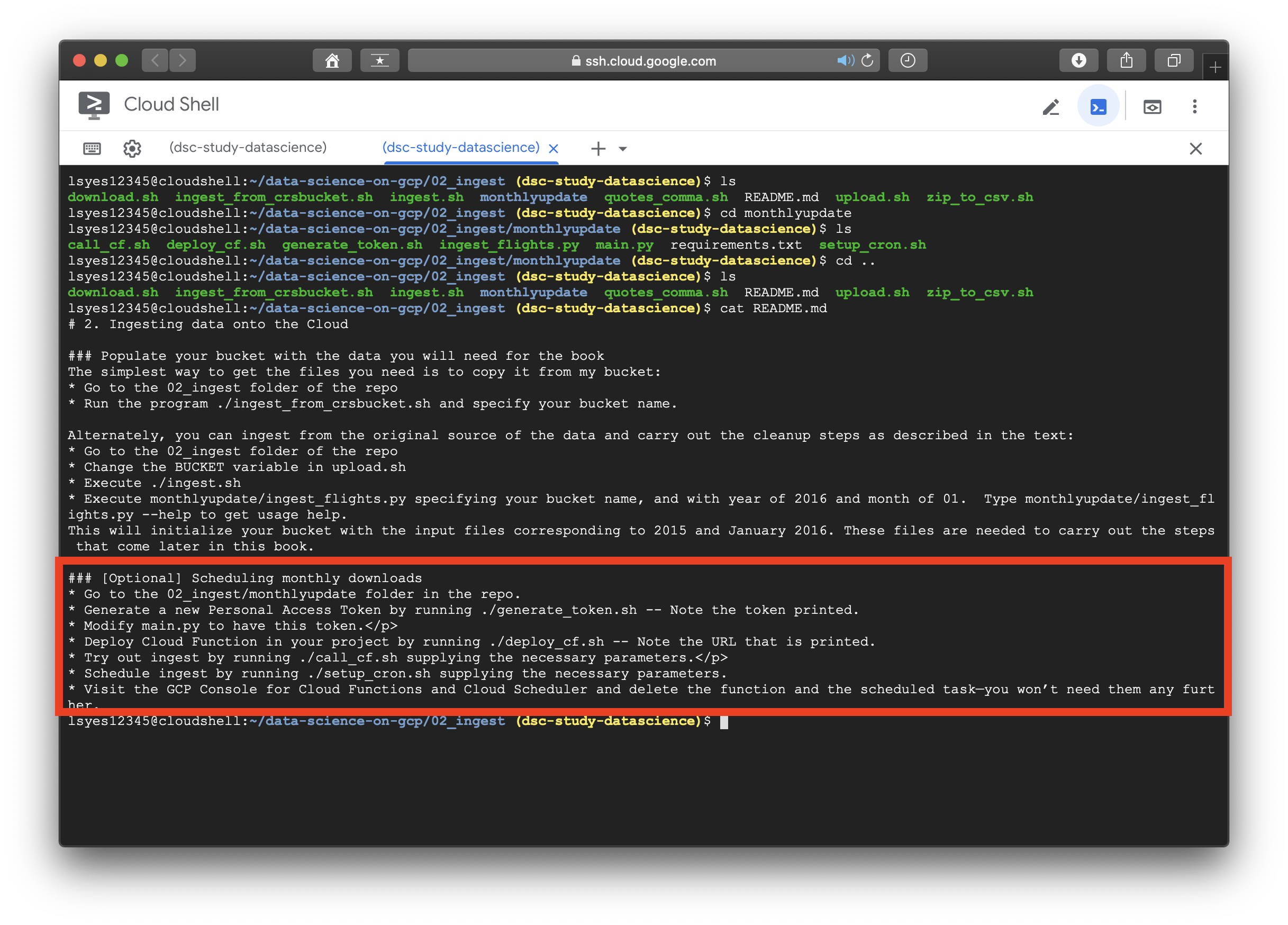
읽으라고 올려놓은 파일을 열어보지도 않은 내 잘못이다.... 안심하고 순서대로 실행시켜보도록 하겠다. 정확한 관련코드는 저자의 깃허브와 저서를 참고하길 권장한다. (너무 다 소개하기엔 날로먹는것 같아...)
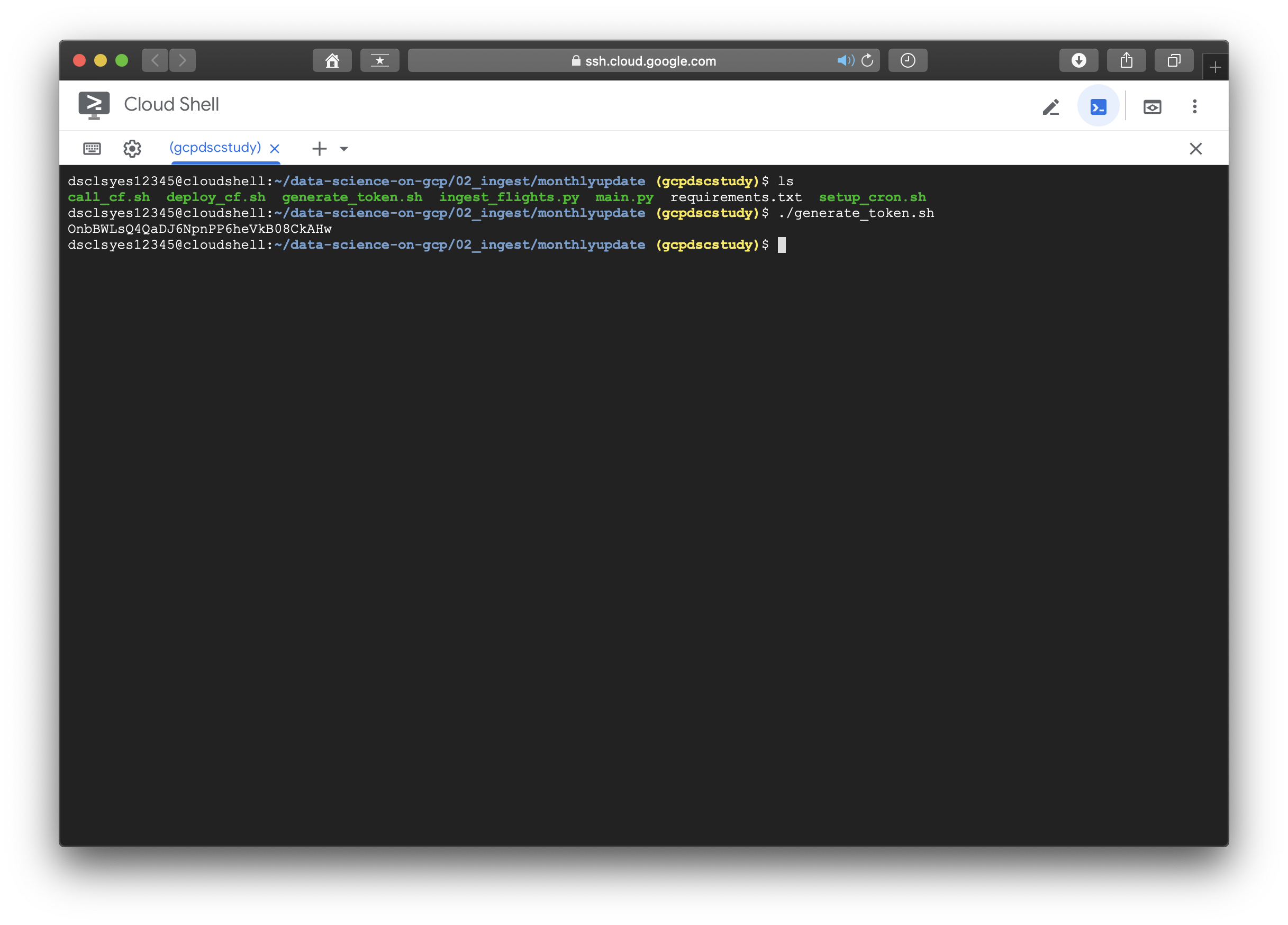
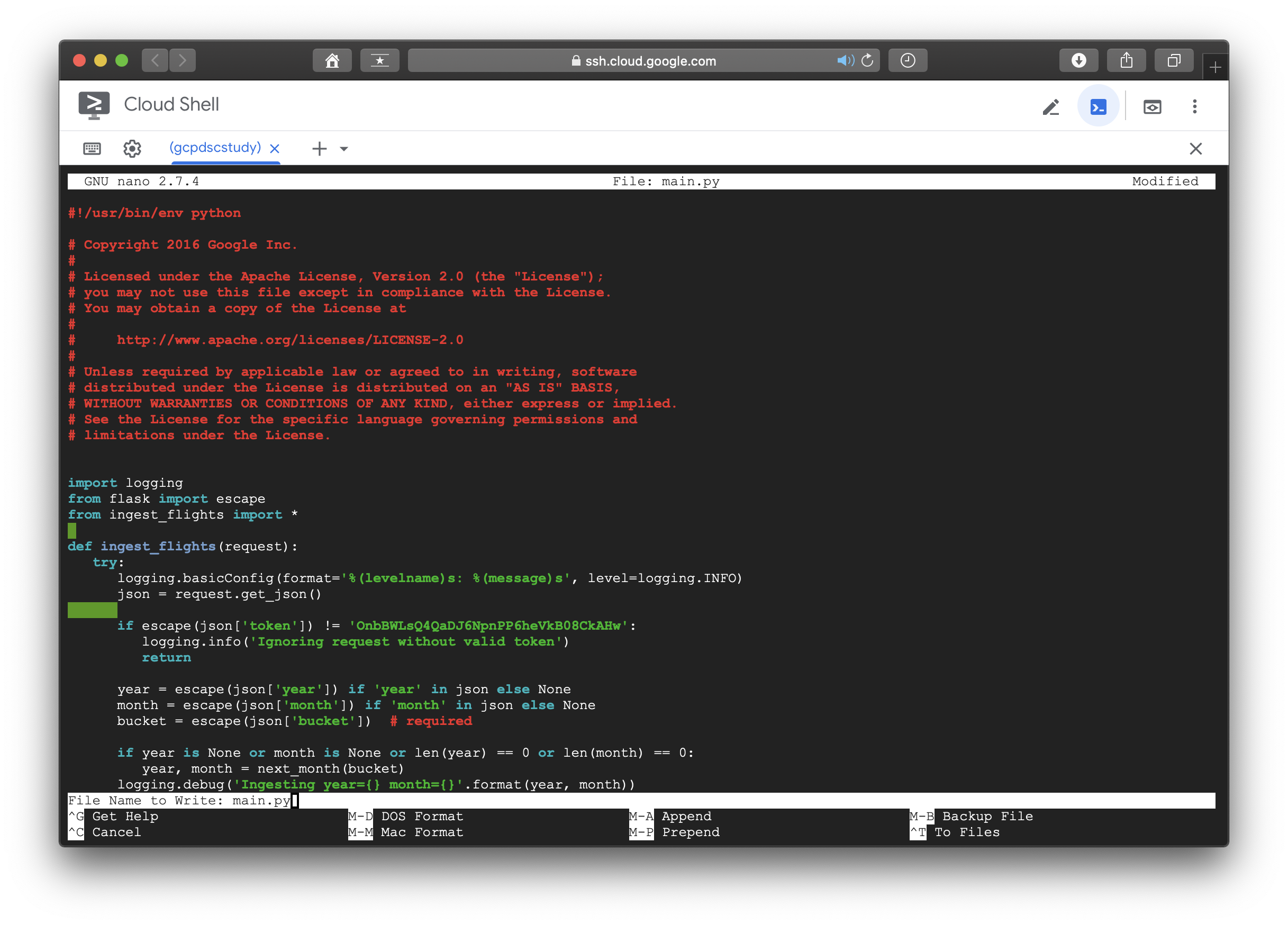
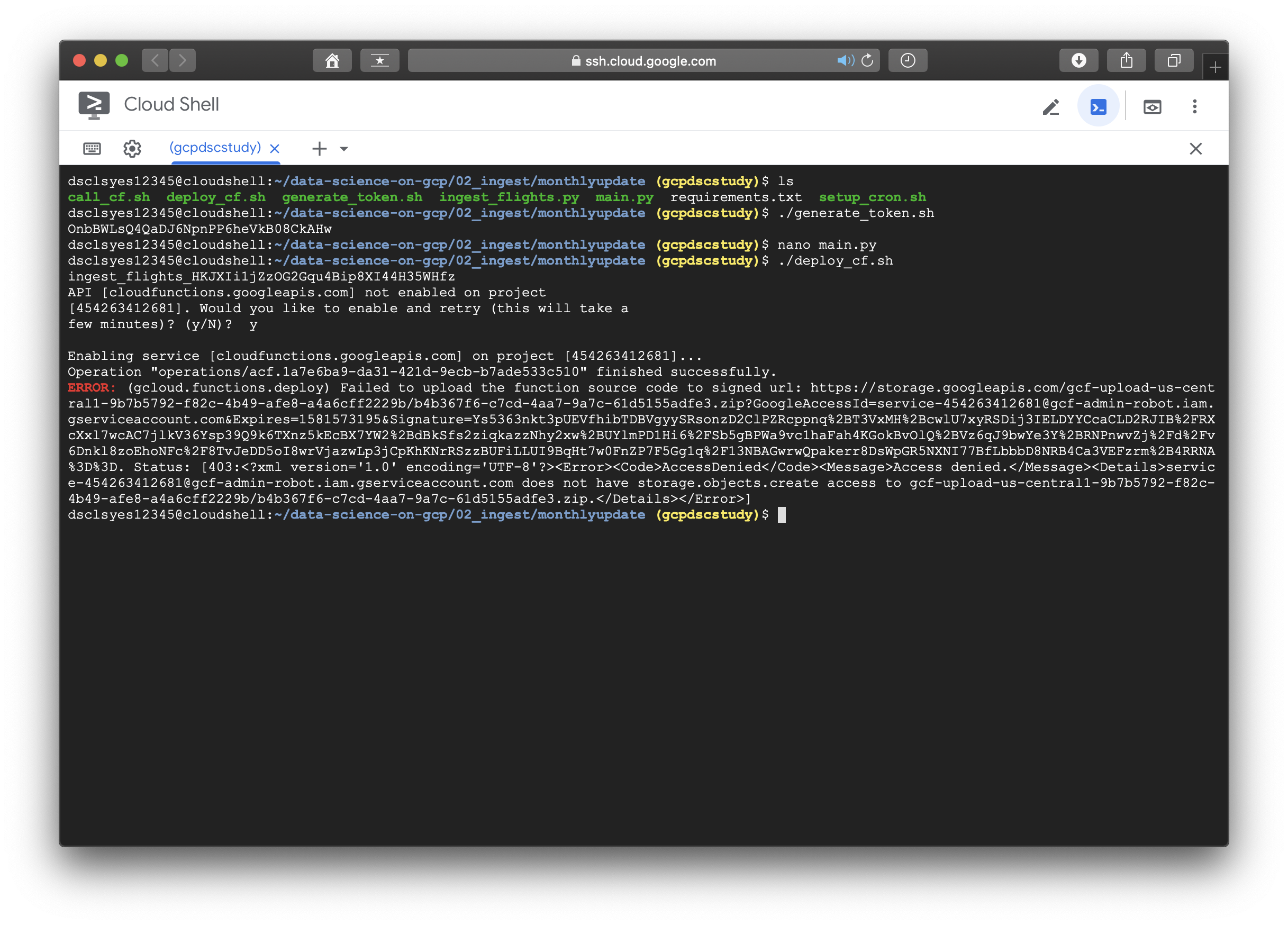
역시나 한방에 될 리가 없다. cloud function api가 enable 되어있지 않는 문제인듯 하니, GCP로 돌아가서 해당 api를 찾아 추가해주도록 한다.
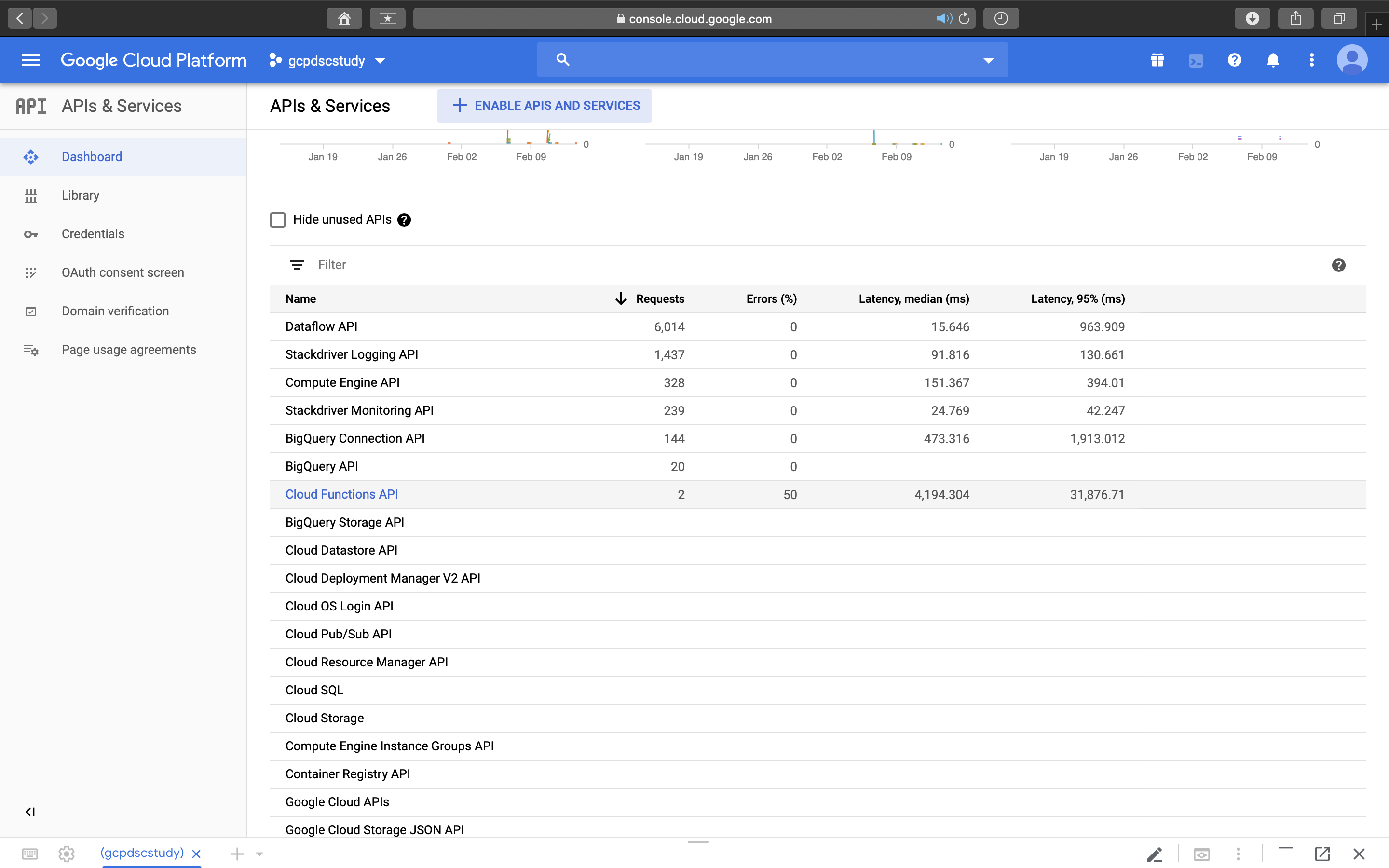
< 이후에도 계속 트러블슈팅 과정이므로 생략하고자 하면 생략해도 된다. >
.......문제는 해결된 줄 알았지만 계속해서 error가 발생했다.... main.py에 ingest_flights_randomstring의 함수명이 필요하다는 내용이였다. cat 커맨드로 deploy_cf.sh와 main.py에서 ingest_flights()라는 function은 있었지만 그 뒤로 저런식으로 random string이 붙는 경우는 없었기에 당황스러웠다.
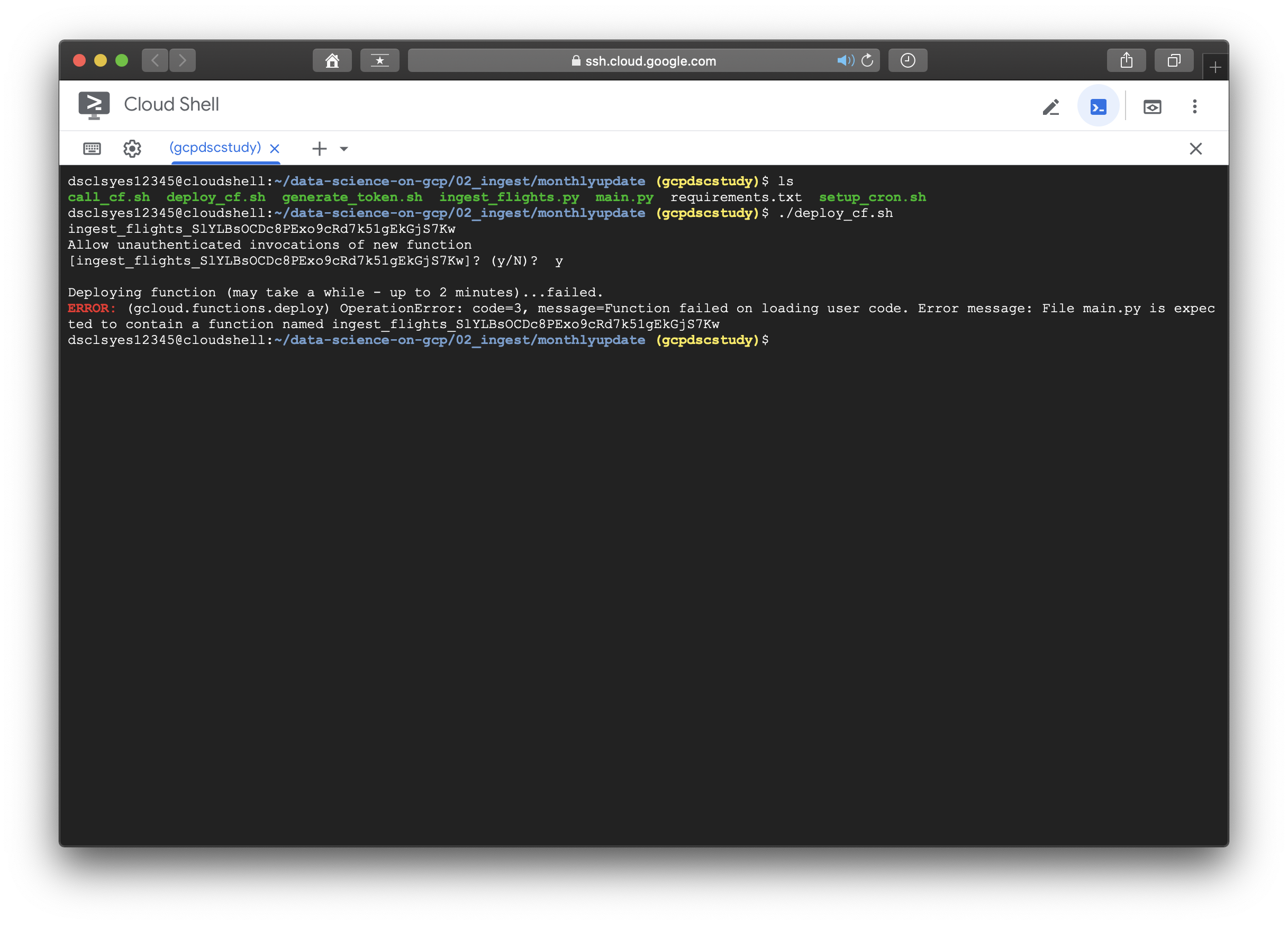
해결방법은 Google Cloud의 deploy reference에서 찾을수 있었다. gcloud 명령어를 사용할 때 NAME에 해당하는 부분에서 --entry-point가 옵션으로 들어가 있지 않는 경우에는 NAME이라는 함수명이 반드시 코드 내부에 정의되어 있어야 한다는 내용이였다.
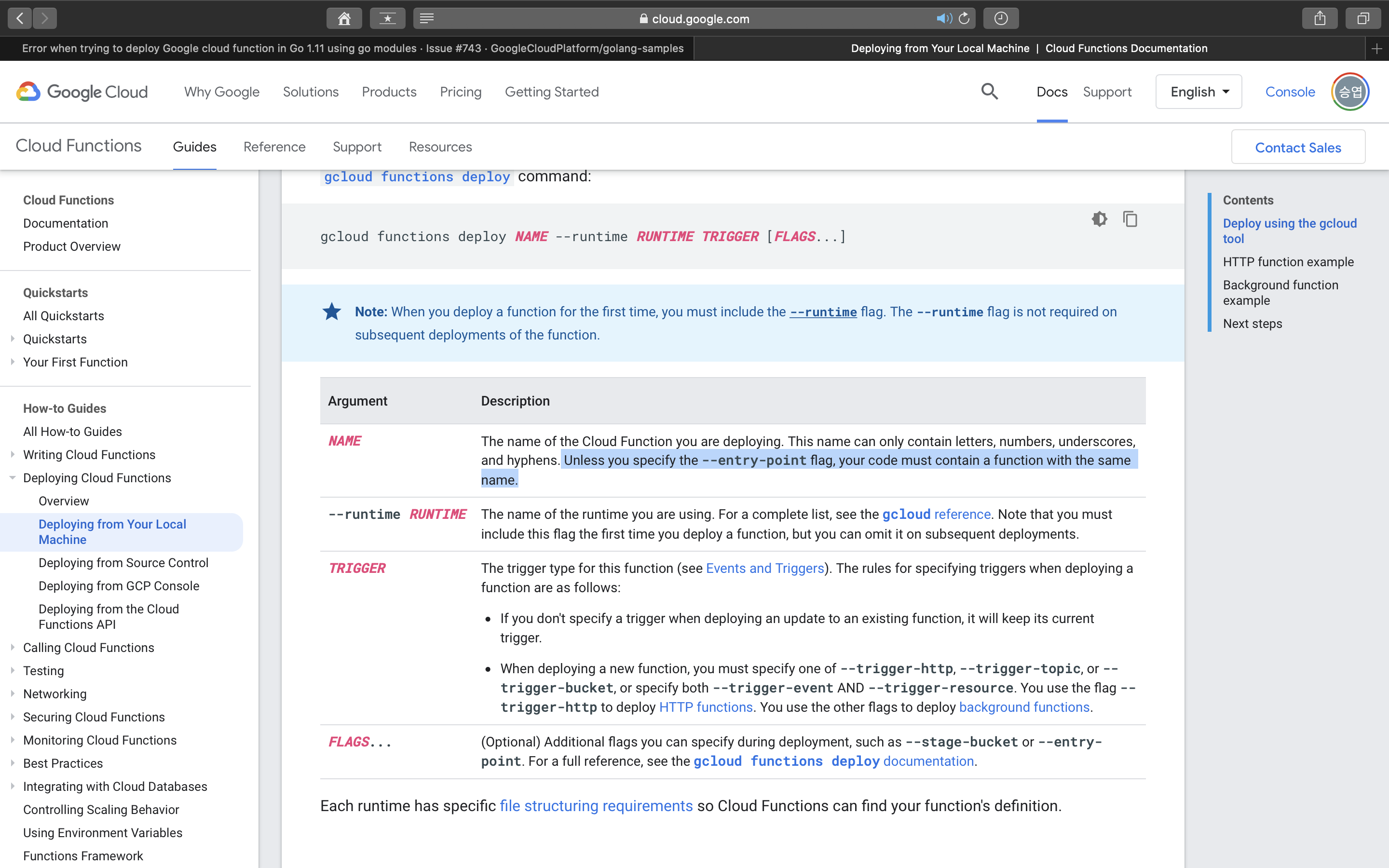
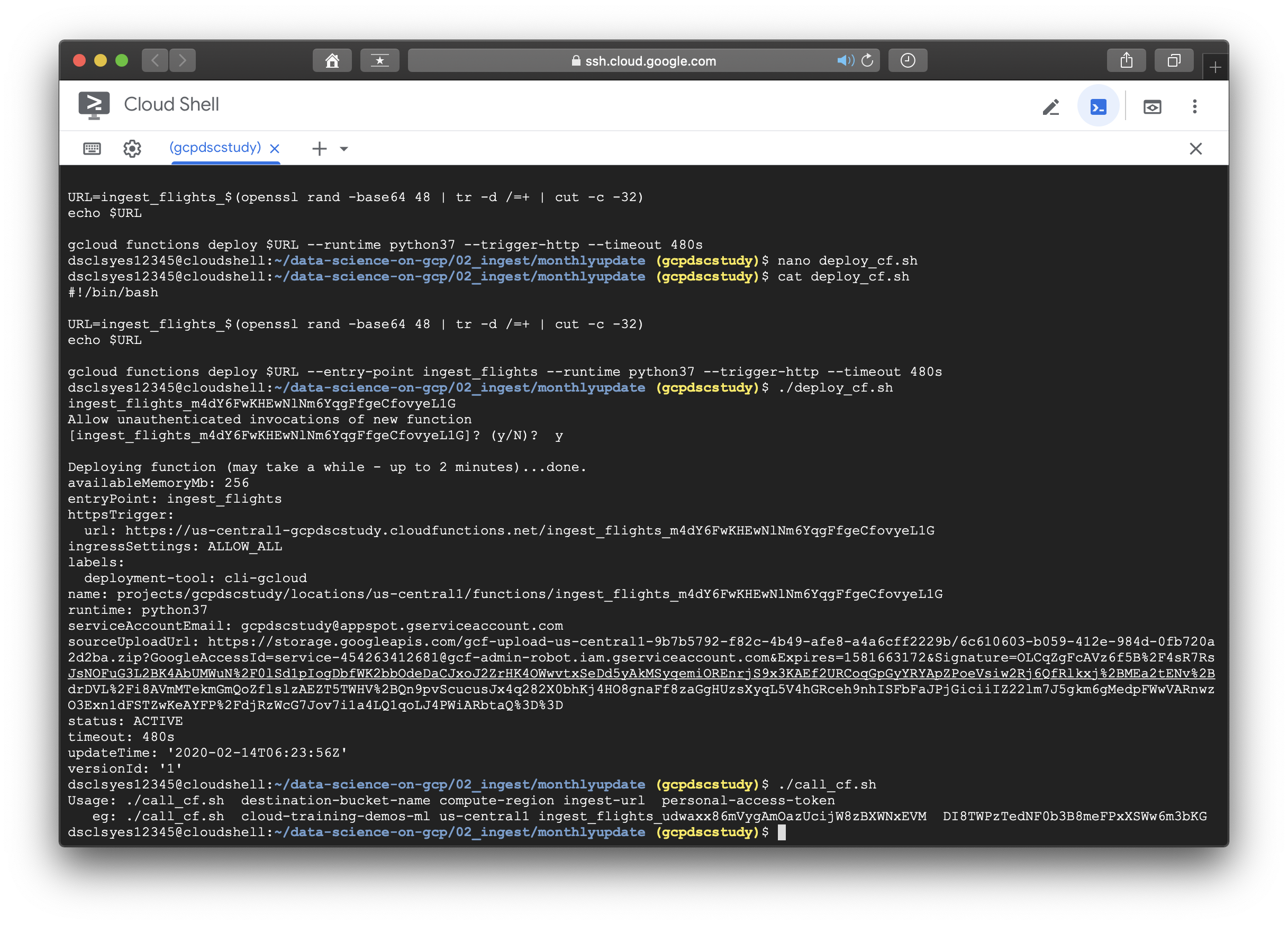
reference에 소개된 대로 --entry-point 뒤에 원래 사용하려던 function인 ingest_flights를 추가해주고 해당 코드를 실행시키니 에러없이 무사히 지나갔다. 이후의 이미지들은 나머지 실습과정을 수행한 것이며 책에 소개되어있지 않고, 새롭게 수정된 README 파일에 있는 내용이다. 실습에 도움이 되도록 아래에 첨부하겠다.
[Optional] Scheduling monthly downloads
- Go to the 02_ingest/monthlyupdate folder in the repo.
- Generate a new Personal Access Token by running ./generate_token.sh -- Note the token printed.
- Modify main.py to have this token.
- Deploy Cloud Function in your project by running ./deploy_cf.sh -- Note the URL that is printed.
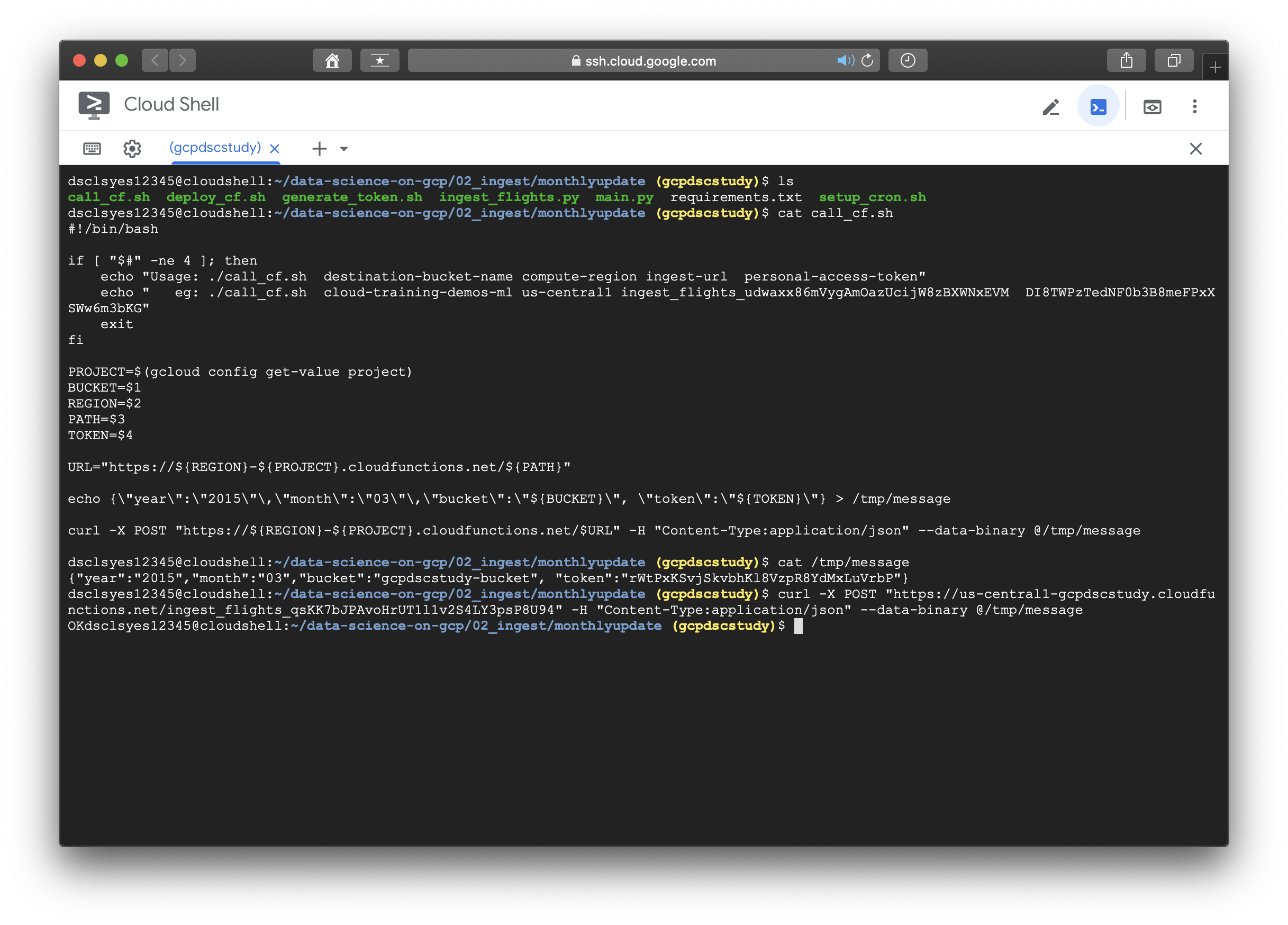
- Try out ingest by running ./call_cf.sh supplying the necessary parameters.
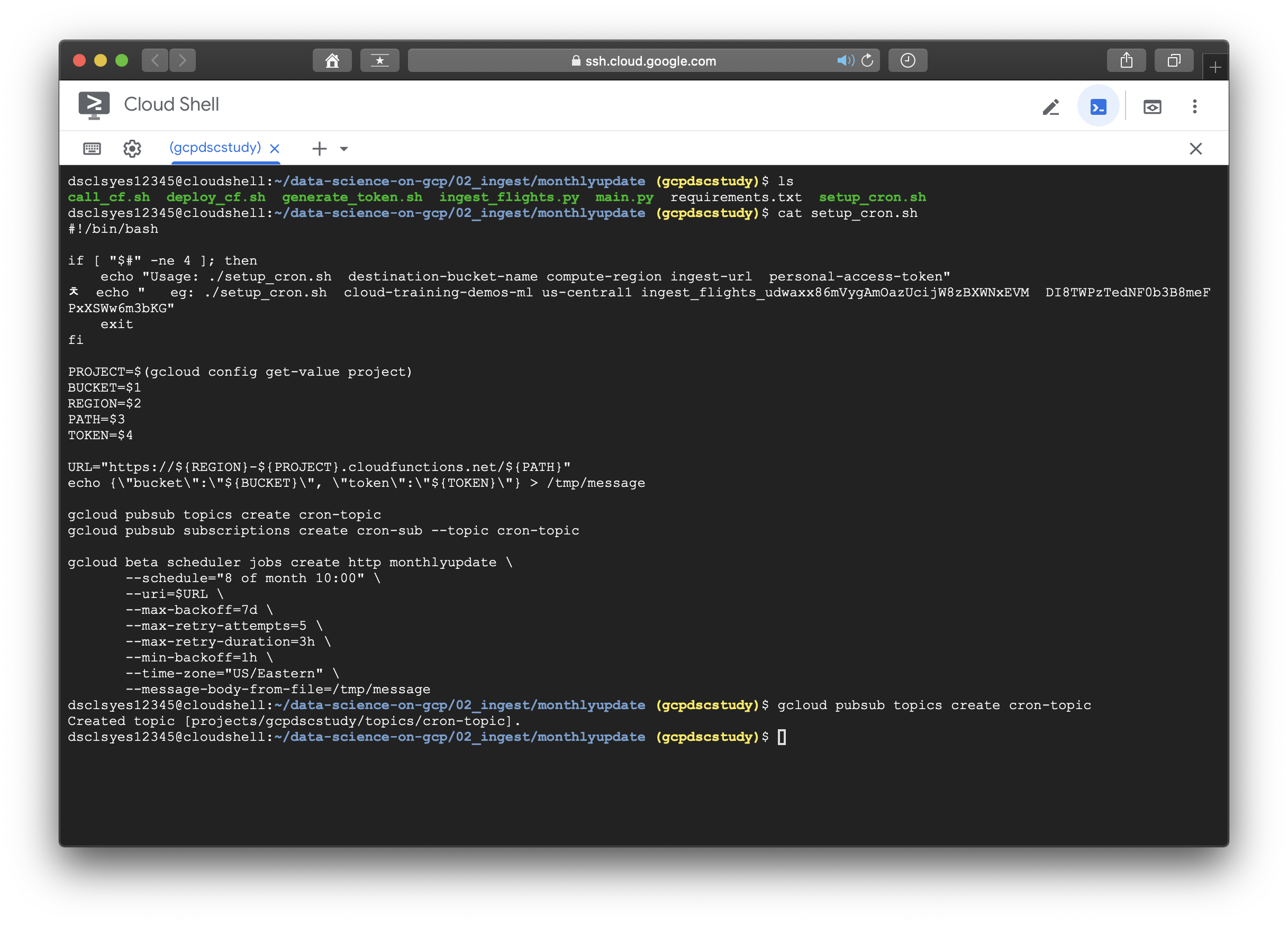
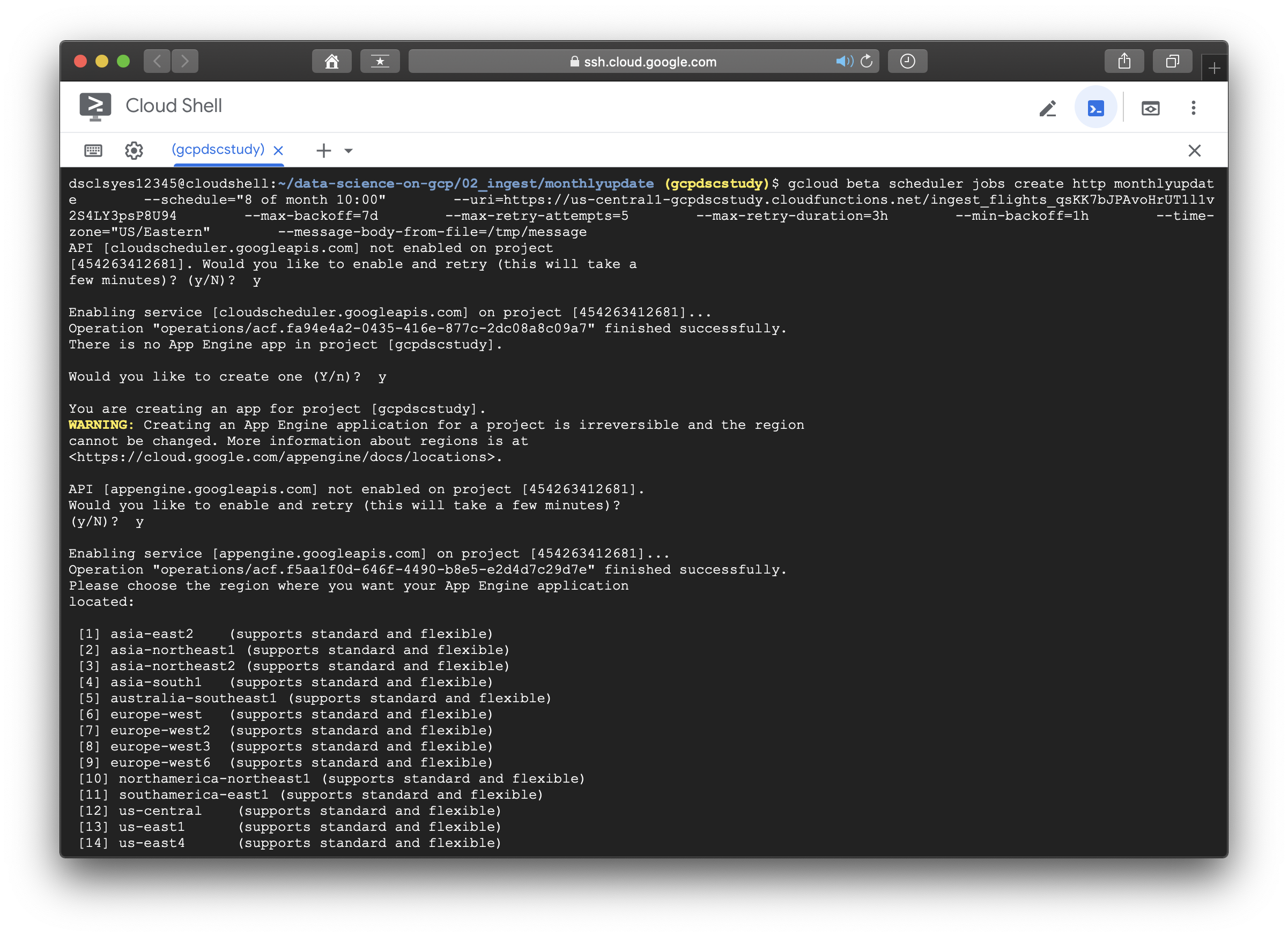
- Schedule ingest by running ./setup_cron.sh supplying the necessary parameters.
- Visit the GCP Console for Cloud Functions and Cloud Scheduler and delete the function and the scheduled task—you won’t need them any further.
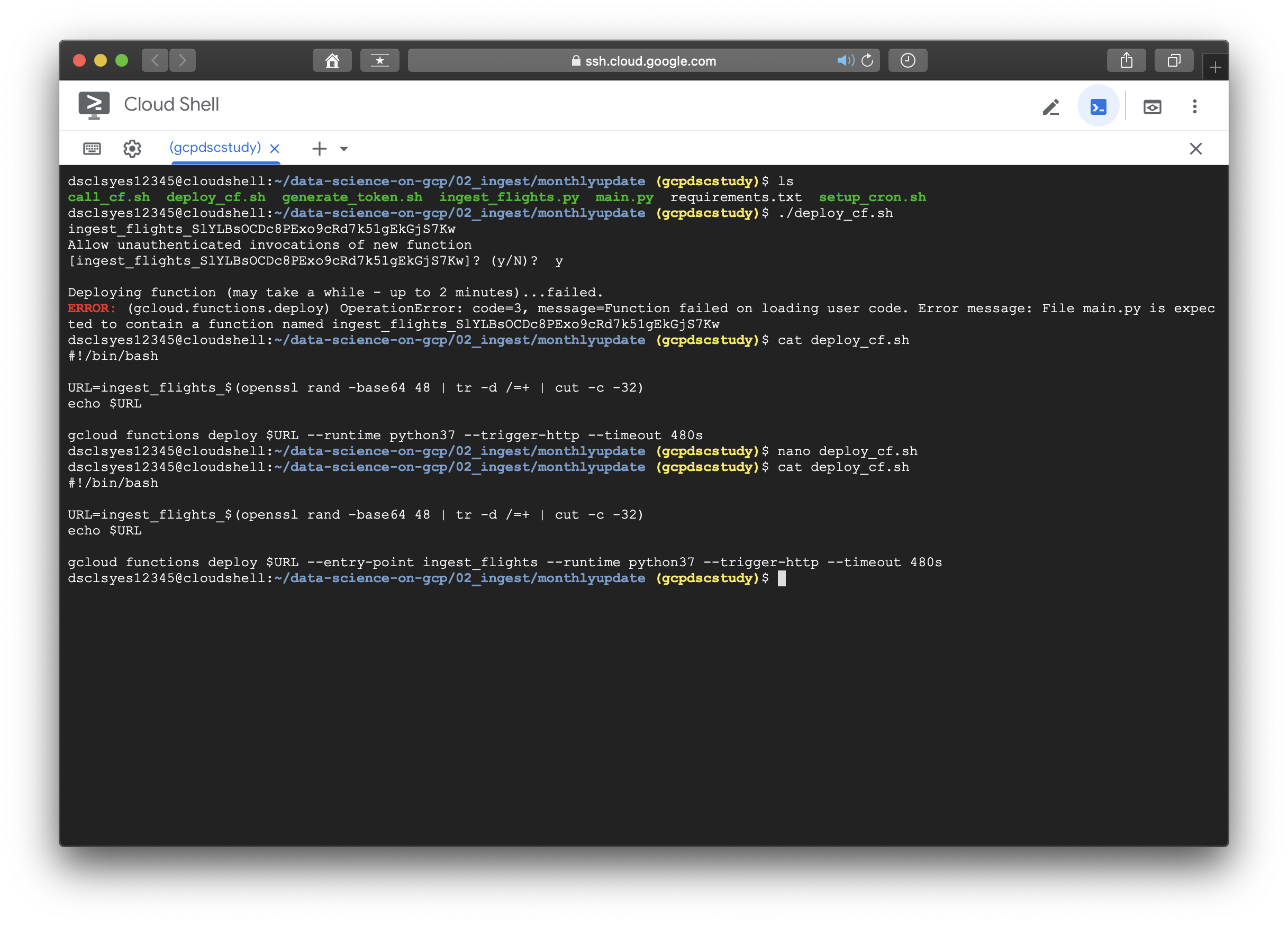
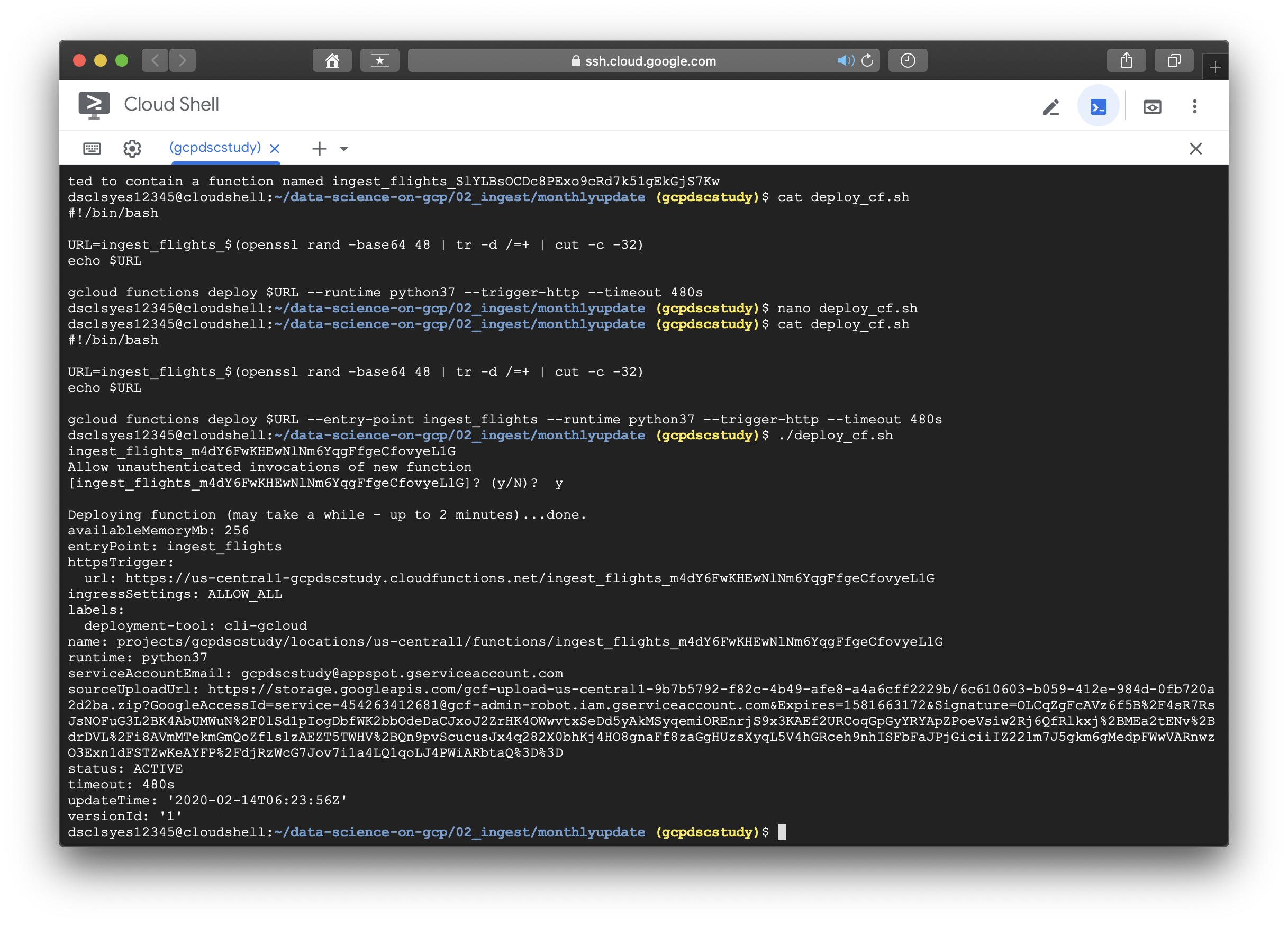
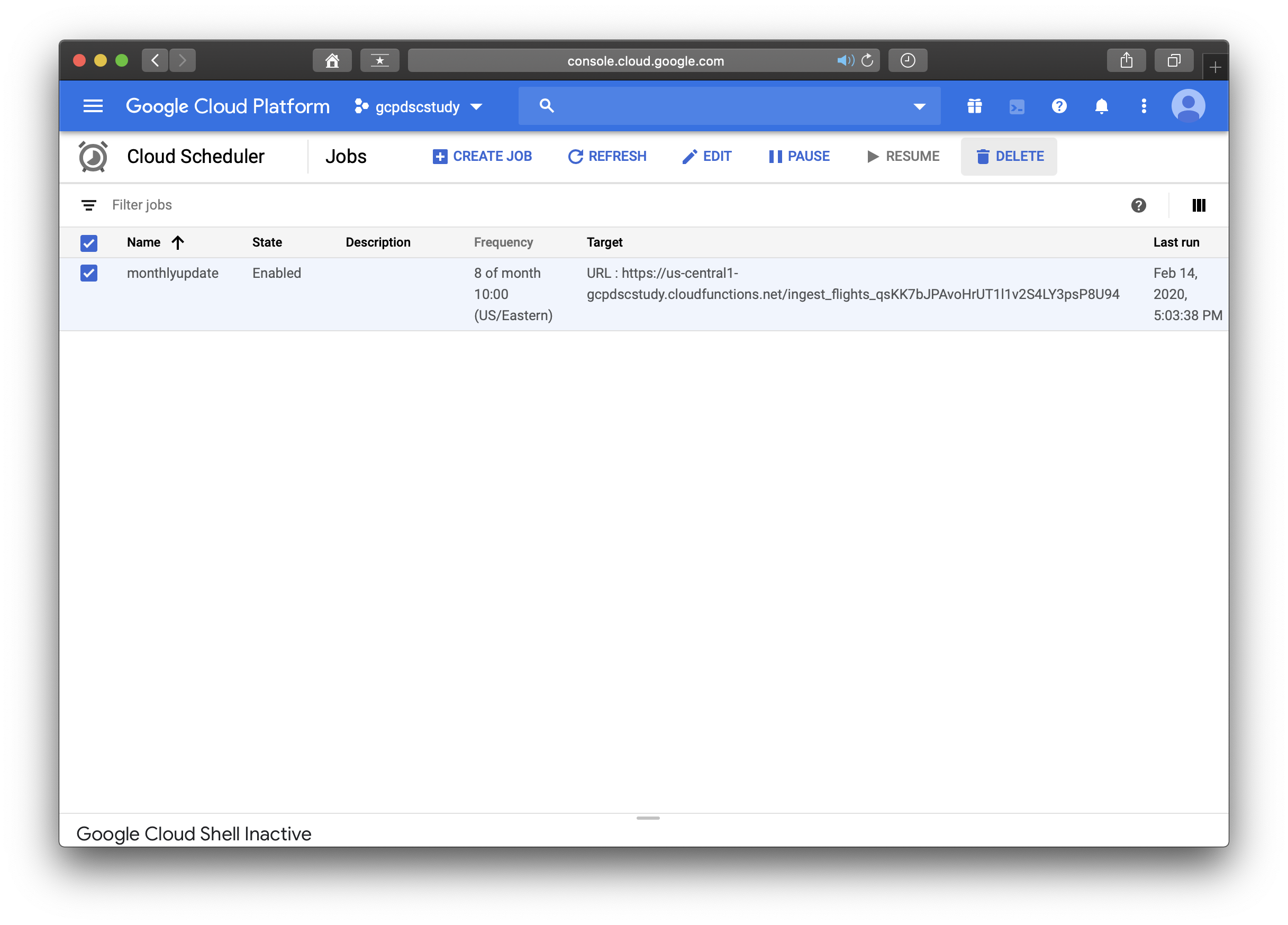
< 다운로드 URL과 BLOB객체에 관련한 설명은 추후에 보충한다. >
"Data Science on the Google Cloud Platform by Valliappa Lakshmanan (O'Reilly). Copyright 2018 Google Inc."
'[Data Engineering] > [Gloud-GCP]' 카테고리의 다른 글
| [GCP] 3-3. DashBoard (0) | 2020.02.18 |
|---|---|
| [GCP] 3-2. Decision Model (0) | 2020.02.18 |
| [GCP] 3-1. How to make Dataset (0) | 2020.02.18 |
| [GCP] 2-1. Fixed Data-set scheduling (0) | 2020.02.18 |
| [GCP] 1. Introduction (4) | 2020.02.18 |



