

산학협력과제(스트레스 예측 모델 개발)을 진행하면서 여러가지 Classification model을 다뤄볼 기회가 있었는데, 그중 하나가 바로 SVM이다. 간단하게 정리해 본다.
< SVM : Support Vector Machine >

Support Vector Machine ( SVM )은 기본적이면서 굉장히 유명한 Classification model이다. 여러 데이터들이 있고, 이 데이터 셋이 분산되어 있다고 가정해 보자. 그러면 위 같은 그림일 것이다. 이때 이 데이터 셋을 잘 나누기 위한 방법이 SVM이다. 이때 구분선과 양 데이터의 Boundary에 해당하는 Support Vector의 거리인 Margin을 최대화 하는 Boundary를 찾는 것이 핵심이다.

마찬가지로 구분선이 정확히 구분지어지지 않는 경우도 있을 것이다. 이런 경우에는 어느정도의 오차를 허용하면서 구분선을 구하게 된다. 또한 이런 SVM중에서, 같은 종류로 묶고 싶은 데이터를을 최대한 많이 포함해서 하나의 Margin 안에 두고자 하는 경우도 있다. 이를 SVR(Support vector Regression)이라고 한다.
결국 모델에서 제일 중요한 부분은 첫번째 그림에 등장하는 hyperplane을 결정하는 것이고, 이를 Decision boundary라고 한다. 위의 선형식을 수식으로 나타낸다고 가정하면,
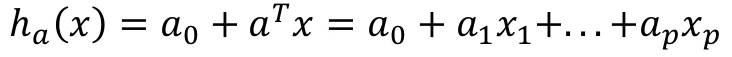
다음과 같으며, 이 값이 0과 비교하여 큰지, 작은지에 따라 데이터의 위치가 선(면) 위인지 아래인지를 알 수 있다. 이를 Decision Rule이라고 한다. 결국 hyperplane은 a^t와 a0에 의해 결정되므로 이를 설정하는 과정이 SVM 모델을 학습시키는 과정이라고 할 수 있다.
>> Lagrange Multipiler 추가
여기서 2차원의 선형적인 데이터를 비선형적으로 나누기 위해서는 kernel을 이용해서 Hyperplane을 구해 나누도록 한다. 다음은 sklearn의 기본 SVM모델을 적용시킨 코드이며, 별도의 파라미터를 부여하지 않았음에도 99.9가 넘는 정확도가 나왔다.
import pandas as pd
from sklearn import svm, metrics
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
swell_hrv = pd.read_csv('data/2. final/datasets/hrv/swell/combined/classification
\combined-swell-classification-hrv-dataset.csv')
original_colum_list = swell_hrv.columns
selected_colum_list = ['MEAN_RR', 'MEDIAN_RR', 'SDRR', 'RMSSD', 'SDSD', 'SDRR_RMSSD', 'HR',
'pNN25', 'pNN50', 'SD1', 'SD2', 'KURT', 'SKEW', 'MEAN_REL_RR',
'MEDIAN_REL_RR']
stress_data = swell_hrv[selected_colum_list]
stress_label = swell_hrv['NasaTLX Label']
train_data, test_data, train_label, test_label = train_test_split(stress_data, stress_label)
# train_data, test_data, train_label, test_label =
# train_data.iloc[:10000],test_data.iloc[:10000],train_label.iloc[:10000],test_label.iloc[:10000]
# 데이터는 10000개로 짤라서 수행
m1 = svm.SVC()
m1.fit(train_data, train_label)
saved_model = pickle.dumps(m1)
joblib.dump(m1, 'SVM_basic_m1.pkl')
model_from_pickle = joblib.load('SVM_basic_m1.pkl')
y_pred_m1 = model_from_pickle.predict(test_data)
print("acc_score : ", metrics.accuracy_score(test_label, y_pred_m1) )
print("confusion_matrix : \n", confusion_matrix(test_label,y_pred_m1))
['class 0', 'class 1', 'class 2']
print("total report : \n",
classification_report(test_label, y_pred_m1, target_names=target_names))처음 acc_score를 찍어보았을 때 너무 잘 나와서 당황했었는데,,,, confusion_matrix를 통한 출력 역시 이상적인 값으로 학습이 된 모습을 확인할 수 있었다...

< 참고 >
[MIT: OCW, Instructor: Patric Winston]
'[ML] > [DeepLearning]' 카테고리의 다른 글
| [ML] 순수 파이썬 코드로 된 딥러닝 모델 분석하기-1. Regression (0) | 2020.10.25 |
|---|
