
728x90
[How abount python]
동일한 WordCount 예제를 이번에는 python으로 작성해 보도록 한다. 먼저 리눅스에 python을 설치해 준다. (공부중인 영상을 참고했는데, 매번 인스턴스 벽돌만 만져서 그런가 역대급 깔끔 설치;;)
sudo apt update
sudo apt-get install python-is-python31. Java는 한 파일에 다 담았지만 python은 mapper와 reducer를 따로 작성해본다. 먼저 mapper를 작성하고, 실행권한을 추가한다. mapper 파일의 역할은 다음과 같다. 단순히 잘라...준다.
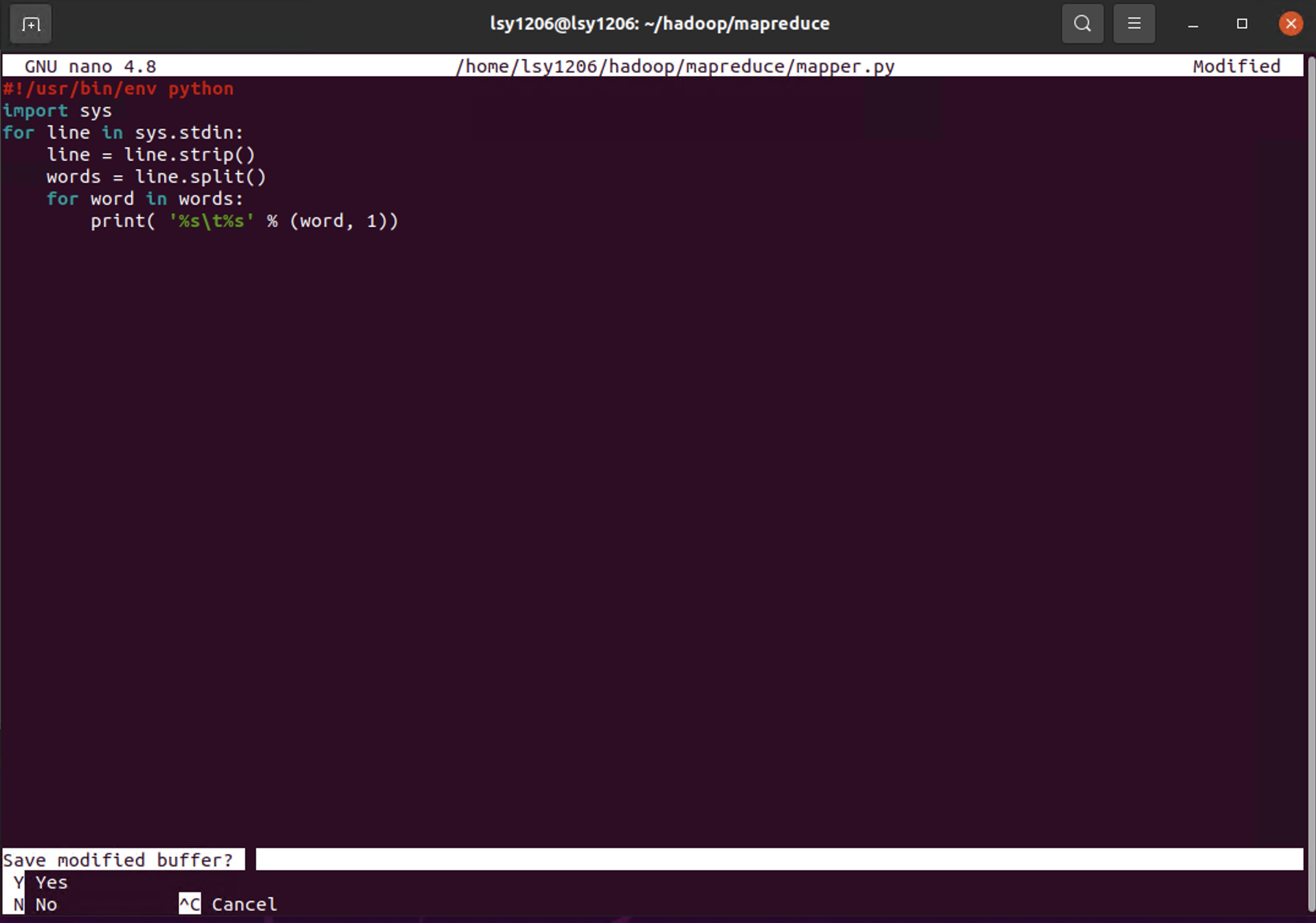

2. 다음은 reducer 파일이다. reducer 또한 들어오는 라인의 tab을 기준으로 첫번째 것만 잘라서, int형으로 변환하고, 만약 word가 같다면 수를 합산해 준다.

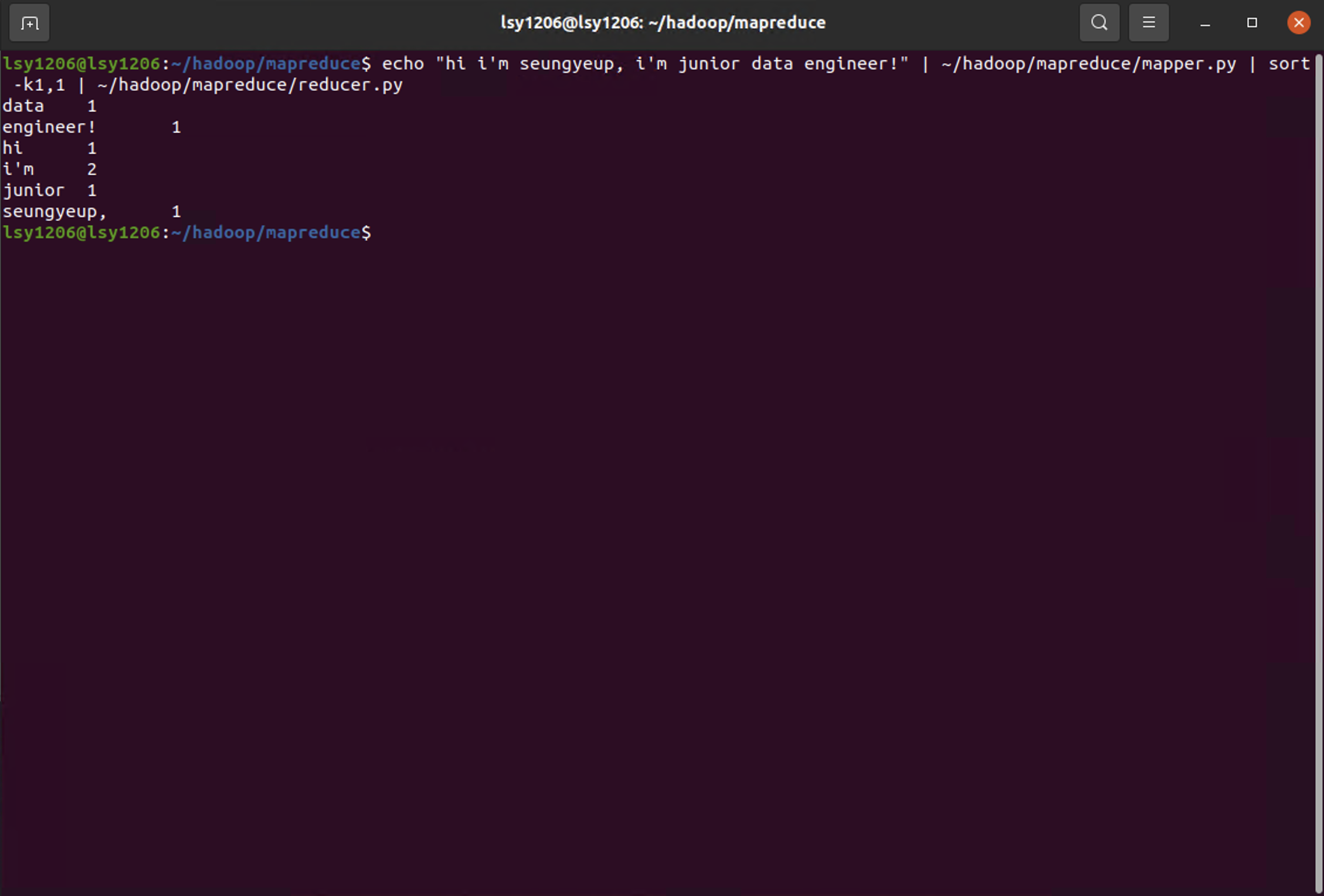
reducer의 동작을 확인하기 위해서는 중복되는 단어가 있는것이 좋아서, 입력하는 문장을 조금 바꾸어보았다.
3. 이번에는 사용자의 입력이 아니라 실제 텍스트 북을 분석해보자! 검색창에 www.gutenberg.org를 치면 plain-text의 서적을 무료로 제공하는 사이트가 나온다. 여기서 적당한 책을 고르고, 다운받는다. 이어서 HDFS에 넣어주도록 하자.

4. hadoop streaming jar파일에 mapper, reducer, input파일, output장소를 지정한 다음 돌려두면 map-reduce job이 실행된다.

5. 결과확인
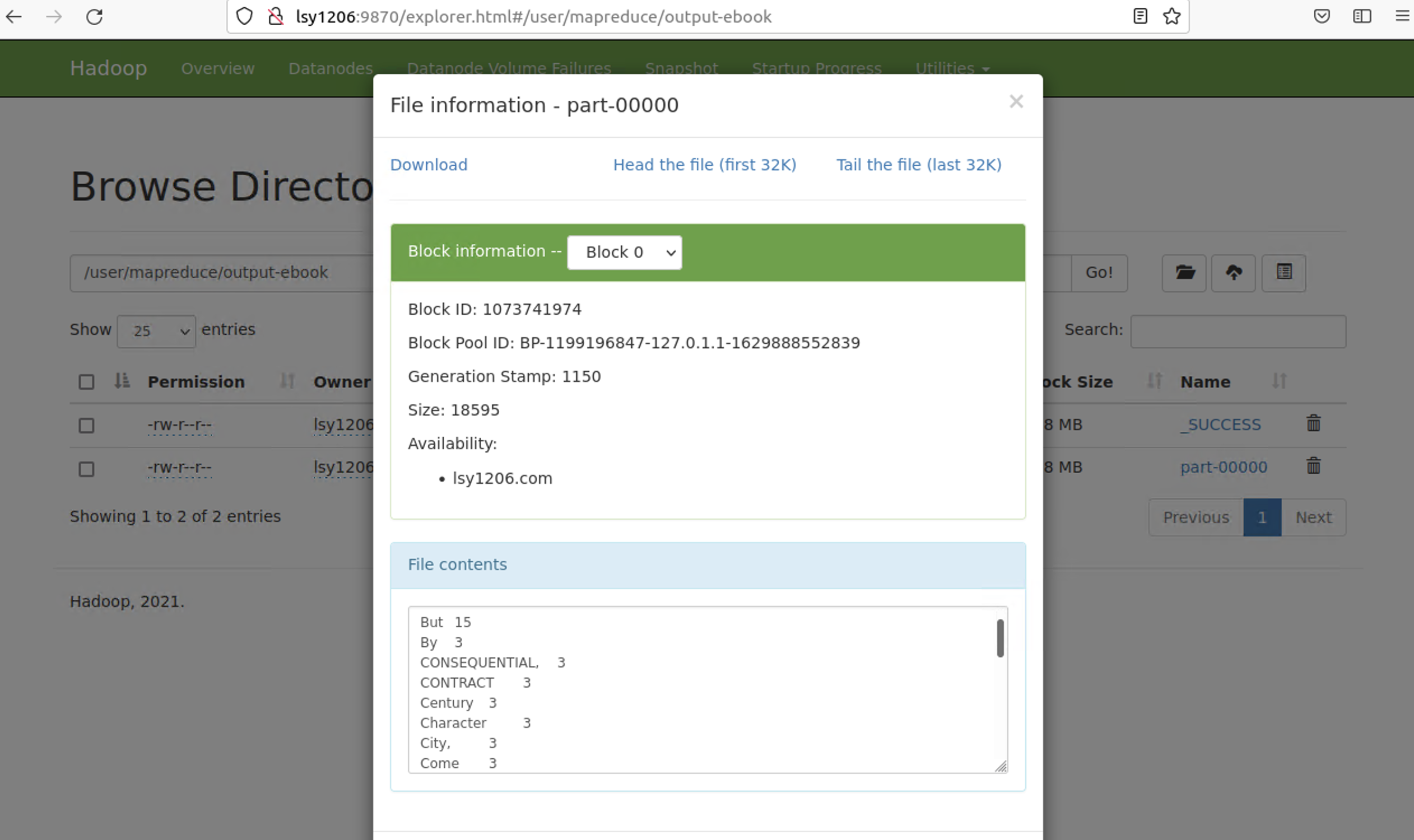
- 끝 -
728x90
'[Data Engineering] > [Hadoop]' 카테고리의 다른 글
| [Hadoop/기록] 7. Hadoop map-reduce (WordCount / Java) (0) | 2021.08.31 |
|---|---|
| [Hadoop/기록] 6. Hadoop Read/Write Architecture (0) | 2021.08.29 |
| [Hadoop/기록] 5. Hadoop Architectures 훑기 (0) | 2021.08.29 |
| [Hadoop/기록] 4. 하둡 User Common commands (0) | 2021.08.28 |
| [Hadoop/기록] 3. Linux -> Hadoop 데이터 적재 과정(fs cmd 복습) (0) | 2021.08.27 |



